
Blitzkurs Theoretische Informatik/ Grammatiken
Natürliche Sprachen wie das Deutsche kann man nicht richtig beschreiben. Formale Sprachen beschreibt man mit Grammatiken. Das ist ein 4-Tupel bestehend aus der Menge der Nichtterminale, der Menge der Terminale, der Menge der Umformungsregeln und dem Startsymbol. Eine Ableitung vom Startsymbol bis zu einem Wort nur aus Terminalen kann man mit dem Ableitungspfeil oder als Ableitungsbaum aufschreiben. Gibt es für ein Wort unterschiedliche Ableitungsbäume, ist die Grammatik mehrdeutig. Gibt es für eine Sprache keine eindeutige Grammatik, ist sie inhärent mehrdeutig. Grammatiken und Sprachen unterteilt man nach der Chomsky-Hierarchie in Typ 0 (rekursiv aufzählbar), 1 (kontextsensitiv), 2 (kontextfrei) und 3 (regulär). Es gibt Sprachen, die nicht vom Typ 0 und damit nicht von Grammatiken beschreibbar sind.
Tag 1[Bearbeiten]
Das Gelernte über formale Sprachen trifft ebenso auf natürliche Sprachen zu. Es verschieben sich nur die Begriffe „Buchstabe“ und „Wort“ zu „Wort“ und „Satz“. Leider ist es kaum möglich, natürliche Sprachen formal zu beschreiben. Zur Beschreibung formaler Sprachen kommen Grammatiken zum Einsatz, die Regeln zur Ableitung von Wörtern aus Nichtterminalen enthalten. Normalerweise gibt man die Regeln in BNF an.
Vielleicht kommt dir eine Sache seltsam vor: Eine Sprache ist eine Menge von Wörtern. Das stimmt in der Theoretischen Informatik, aber es erscheint zunächst sinnlos, wenn man versucht, diese Definition auf natürlich gewachsene Sprachen zu übertragen. Nicht jeder Satz, der nur aus deutschen Wörtern besteht, ein Satz deutscher ist. Reihenfolge ist die wichtig.
Dieser Widerspruch löst sich schnell auf, wenn man erkennt, dass der Begriff „Wort“ in Bezug auf die Theorie der formalen Sprachen ungefähr vergleichbar ist mit dem umgangssprachlichen Begriff „Satz“. Es gehört also das Wort „Das ist ein deutscher Satz.“ zur Sprache während „Könnte sein Satz das deutscher ein.“ nicht dazu gehört. „Satz“, „sein“, „könnte“ und so weiter sind dann Buchstaben des Alphabetes Das ABC hat aber nichts mit zu tun, denn die Buchstaben braucht man nicht noch weiter zu teilen.



Es ist der Wunschtraum vieler Linguisten, natürliche Sprachen mit den Begriffen der Theoretischen Informatik formalisieren zu können und die Grenze zwischen formalen und natürlichen Sprachen aufzuheben. Eine vollständige Formalisierung einer Sprache ist unglaublich kompliziert, häufig überhaupt nicht möglich. Aber man kann tatsächlich relativ einfach gewisse Teilaspekte einer Sprache mathematisch korrekt definieren. Sieh dir dazu das folgende Beispiel an:

Die Wörter der hier beschriebenen Sprache sind „Sie baut Honig.“, „Es angelt Blumen.“, „Er näht Zierfische.“ und viele mehr. Siebenundzwanzig grammatikalisch korrekte Sätze kann man bilden. Das sind natürlich längst nicht alle. Da das Deutsche wie andere Sprachen auch die Möglichkeit bietet, beliebig viele Nebensätze und Attribute einzuschieben, ist die Anzahl der richtig gebildeten deutschen Sätze sogar unendlich. Der französische Schriftsteller Marcel Proust ist für seine erhellenden Schachtelsätze berühmt. Der erste Satz aus dem Roman À l'ombre des jeunes filles en fleurs lautet:

- „Ma mère, quand il fut question d'avoir pour la première fois M. de Norpois à dîner, ayant exprimé le regret que le Professeur Cottard fût en voyage et qu'elle-même eût entièrement cessé de fréquenter Swann, car l'un et l'autre eussent sans doute intéressé l'ancien Ambassadeur, mon père répondit qu'un convive éminent, un savant illustre, comme Cottard, ne pouvait jamais mal faire dans un dîner, mais que Swann, avec son ostentation, avec sa manière de crier sur les toits ses moindres relations, était un vulgaire esbrouffeur que le Marquis de Norpois eût sans doute trouvé selon son expression, «puant».“
Allein das Alphabet ist eine unvorstellbar große Menge. Wenn man jedes zusammengesetzte Substantiv als einzelnen Buchstaben betrachtet, ist das Alphabet unendlich. Donaudampfschiffahrtselektrizitätenhauptbetriebswerkbauunterbeamtengesellschaft ist noch lange nicht das Ende der Fahnenstange. Eine annähernd vollständige Formalisierung des Deutschen ist also wahrhaftig nicht in Sicht.
Es wird nun Zeit, zu erläutern, wie man Sprachen elegant beschreiben und einordnen kann. Bisher hast du zur Beschreibung einer Sprache mehr oder weniger alle Wörter aufgezählt. Wenn sich die Wörter ähneln, kann man zwar ökonomischer vorgehen, indem man die Konkatenation und Mengenoperatoren nutzt, aber es geht auch noch einfacher: Ebenso wie korrekt gebildete deutsche Sätze aus Einzelwörtern von grammatikalischen Regeln beschrieben werden, gibt es auch für die meisten formalen Sprachen, mit denen man es in der Praxis zu tun hat, Grammatiken, die die jeweilige Sprache hinreichend beschreiben.
Es gibt kurze Übersichten über die deutsche Grammatik und es gibt hundert Seiten lange Abhandlungen. Es gibt aber keine allumfassende systematische Beschreibung. Das liegt, wie oben gezeigt, daran, dass die deutsche Sprache sehr komplex ist und unzählige Besonderheiten und Ausnahmen aufweist, die sich mit Worten besser beschreiben lassen als mit mathematischen Symbolen. Oft genügt auch ein grober Überblick über einen Teilaspekt der Grammatik.
Wenn aber der Informatiker von einer Grammatik spricht, meint er eine vollständige Liste formalisierter eindeutiger Regeln zur Bildung von Wörtern im Sinne der Theoretischen Informatik (also Sätzen).
So könnte das Regelwerk einer Grammatik aussehen:

Es handelt sich um die Regeln einer Grammatik zur Bildung der oben beschriebenen vereinfachten deutschen Sprache. Die Bildung der Wörter geschieht folgendermaßen: Man fängt beim Startsymbol an. Das Wort hat zunächst die Länge drei: Es besteht aus den drei „Buchstaben“ und Die Großschreibung deutet an, dass es sich nicht um Buchstaben aus dem zugrundeliegenden Alphabet handelt. Diese Zeichen, man nennt sie Nichtterminale, müssen also noch durch richtige Buchstaben, so genannte Terminale, ersetzt werden. Zum Beispiel ist dort die Regel Wendet man sie an, lautet das Zwischenergebnis Ein vollständig abgeleitetes Wort aus der Sprache, die von der Grammatik beschrieben wird, ist Insgesamt kann man siebenundzwanzig Wörter bilden.







Lasst uns die Sache an dieser Stelle gleich etwas vereinfachen! Die mathematisch korrekte Notation der Buchstabenfolgen mit den spitzen Klammern und den Kommata zwischen den Folgengliedern ist doch recht umständlich. Man legt normalerweise fest, dass alle Symbole optisch nur aus einem Buchstaben bestehen. Dann kann man sie lückenlos aneinander schreiben. Zum Beispiel so:

Die Nichtterminale, also die Symbole, die noch abgeleitet werden müssen, werden mit Großbuchstaben dargestellt. Aus diesem Grunde sollten die Alphabete, über denen man Sprachen definiert, keine Großbuchstaben enthalten. Verwechslungen wären die Folge. Also Terminale sind normalerweise Kleinbuchstaben oder Ziffern. In diesem Fall kommt noch das Leerzeichen (als Bindestrich dargestellt) und der Punkt dazu.
Zur weiteren Vereinfachung kann man Ersetzungsregeln, deren linke Seiten identisch sind, mit vertikalen Strichen zusammenfassen. Zum Beispiel:

Nach der Anwendung dieser Vereinfachungen sieht die Regelliste doch schon viel sympathischer aus. Wenn Produktionsregeln derart vereinfacht sind, spricht man von der Backus-Naur-Form (BNF) nach den Informatikern John Warner Backus und Peter Naur. Man gibt Regeln normalerweise in BNF an.






Tag 2[Bearbeiten]
Eine Grammatik ist ein 4-Tupel aus der Menge der Nichtterminale, dem Alphabet, der Menge der Produktionsregeln und dem Startsymbol. Meistens gibt man aber nur an. Zur Definition der Regeln schreibt man den Definitionspfeil: bei der Ableitung einer Satzform wird aber der Relationspfeil geschrieben: Die Ableitungen können manchmal als Ableitungsbaum aufgeschrieben werden. Wenn es für ein vollständig abgeleitetes Wort nicht nur verschiedene Ableitungspfade, sondern auch noch unterschiedliche Ableitungsbäume gibt, ist die Grammatik mehrdeutig. Sprachen, die nicht mit einer eindeutigen Grammatik beschrieben werden können, sind inhärent mehrdeutig.







Eine einfache Liste von Ersetzungsregeln ist noch keine Grammatik. Es fehlt zum Beispiel die Information, welches Nichtterminal das Startsymbol ist. Man nennt es normalerweise aber diese Information gehört unbedingt in die Beschreibung der Grammatik. Außerdem gehört das Alphabet, das die Sprache verwendet, und eine Auflistung aller Nichtterminale dazu. Man notiert eine Grammatik als 4-Tupel:
Dabei ist die Menge aller Nichtterminale (Variablen), die Menge aller Terminale, also das Alphabet, die Menge aller Produktionsregeln und als Element von das Startsymbol.



Jetzt kann man weiter spezifizieren. Im gestern beschriebenen Fall gilt jetzt folgendes (die Wörter werden hier zur Vereinfachung als Buchstaben aufgefasst):

Die Grammatik ist jetzt ausreichend beschrieben und die Sprache, die diese Grammatik bildet, ist genau die genannte Sprache aus siebenundzwanzig deutschen Sätzen.


Wenn man mit Grammatiken rechnet und sie vergleicht, braucht man diese Formalien. Definiert man zum Beispiel zwei Grammatiken als und dann ist klar, dass beide die gleiche Terminalenmenge verwenden. Wenn man aber eine einzelne Grammatik angeben möchte, dann schreibt man normalerweise nur die Produktionsregeln vollständig in BNF auf und spart sich den Rest. Man weiß ja, dass das Startsymbol ist und man sieht ja, welche die relevanten Elemente von und sind.


Wie wendet man denn nun eine Grammatik richtig an? Das Ziel ist es, aus dem Nichts Wörter zu erschaffen. Formal ausgedrückt: Das Startsymbol wird zu einer Folge von Terminalen abgeleitet. Ableiten heißt, die Regeln anzuwenden. Nach der obigen Beispielgrammatik kann zunächst nur folgendermaßen abgeleitet werden: wobei der Pfeil mit zwei horizontalen Linien wichtig ist. Für den nächsten Ableitungsschritt gibt es aber mehrere Möglichkeiten. Man könnte zum Beispiel schreiben oder In jedem Ableitungsschritt wird genau eine Regel aus angewendet. Welche, ist egal. Man spricht diesen Doppelpfeil als „ geht unter unmittelbar über in “ aus. Dieser Relationspfeil ist vom Definitionspfeil, der in den Produktionsregeln vorkommt, abzugrenzen: spricht man „ ist definiert als “ aus. Während diese Definition allgemeingültig ist, kann die Ableitung vom Startsymbol über verschiedene Satzformen bis zu einem Wort beliebig verlaufen, sofern die Produktionsregeln gewisse Variationsmöglichkeiten offenhalten. Zwei mögliche Ableitungen sind
und
Die Angabe, unter welcher Grammatik die Relation gilt – den tiefgestellten Buchstaben rechts vom Ableitungspfeil – kann man großzügig weglassen, wenn es sowieso nur um eine einzelne Grammatik geht.









Manche Grammatiken erlauben eine übersichtlichere Darstellung solcher Ableitungen:

Dieser Ableitungsbaum gehört sowohl zu der Ableitung
als auch zu
Egal, ob man die Linksableitung oder die Rechtsableitung bevorzugt, es gibt zu jedem Wort nur genau einen Ableitungsbaum. Man sagt, die Grammatik ist eindeutig. Eine mehrdeutige Grammatik ist demgegenüber die folgende:



Man kann nun wieder verschiedene Ableitungen für das Wort „abcd“ finden:
und
Der Haken ist, dass auch die Ableitungsbäume verschieden sind:

Die Grammatik ist mehrdeutig. Diese Mehrdeutigkeit kann man auch auf Sprachen übertragen. Man bezeichnet eine Sprache als inhärent mehrdeutig, wenn es nicht möglich ist, eine eindeutige Grammatik für diese Sprache zu finden. Heißt die oben angegebene mehrdeutige Grammatik dann ist die Sprache
aber nicht inhärent mehrdeutig, denn man kann eine eindeutige Grammatik angeben:





Jetzt gibt es für jedes Wort nur eine Ableitung und damit auch nur einen Ableitungsbaum. ist eindeutig.


Tag 3[Bearbeiten]
Die Chomsky-Hierarchie unterteilt die Grammatiken. Die meisten Grammatiken sind vom Typ 0, einige außerdem vom Typ 1. Die Einschränkung für Typ-1-Grammatiken (kontextsensitive) ist für alle Das Wortproblem ist für Typ-1-Grammatiken entscheidbar. Typ-1-Grammatiken sind darüberhinaus vom Typ 2 (kontextfrei), wenn für alle gilt Das Leerheitsproblem ist für Typ-2-Grammatiken entscheidbar; es gibt einen effizienten Algorithmus für Typ-2-Grammatiken, die in CNF vorliegen.




Es bietet sich an, Sonderfälle von Grammatiken zu untersuchen. Für viele Grammatiken, mit denen man in der Praxis häufig zu tun hat, gelten gewisse Regeln, die einem das Leben vereinfachen, die man aber leider nicht auf alle Grammatiken übertragen kann. Noam Chomsky, ein Linguist und Libertärer, klassifizierte die Grammatiken nach ihrer Handhabbarkeit. Nach seiner Einteilung sind alle Grammatiken vom Typ 0. Es gibt einige, die nicht nur vom Typ 0, sondern auch vom Typ 1 sind. Eine Typ-1-Grammatik zeichnet sich dadurch aus, dass man nicht nur Wörter, die der beschriebenen Sprache angehören, generieren kann, sondern auch umgekehrt feststellen kann, ob ein gegebenes Wort irgendwie von dieser Grammatik erzeugt werden kann. Die Einschränkung für Typ-1-Grammatiken besteht darin, dass die linke Seite jeder Produktionsregel höchstens genauso lang ist wie die dazugehörige rechte Seite. Dazu ein Beispiel:

Das sind fünf Regeln. Bei den letzten dreien besteht die linke Seite aus mehr Symbolen als die rechte Seite. ist in diesem Sinne kein Symbol. Es hat ja die Länge 0. Es ist deshalb möglich – in diesem Falle sogar zwingend nötig –, dass die Länge der Satzformen während der Ableitung nicht immer nur ansteigt. Denkbar ist der folgende Ableitungsschritt: Die Anzahl der Symbole sinkt hier von sechs auf fünf. Dagegen ist diese Grammatik vom Typ 1:
Die Ableitung eines Wortes weist immer die folgende Struktur auf:
Da keine linken Seiten der Produktionsregeln länger sind als die rechten Seiten, werden die Satzformen während der Ableitung niemals wieder kürzer.




Wenn man nun wissen will, ob ein Wort von einer Typ-1-Grammatik gebildet werden kann, probiert man einfach systematisch alle möglichen Ableitungen aus, ausgehend vom Startsymbol. Wenn man die Länge des gegebenen Wortes überschritten hat, kann man aufhören, denn aus einer längeren Satzform kann das Wort nicht gebildet werden. Lass uns probieren, ob die oben angegebene Grammatik das Wort „aaabbb“ bilden kann. Bei der folgenden Grafik handelt es sich nicht um einen Ableitungsbaum.

Hier sind alle möglichen Satzformen dargestellt, die höchstens sechs Zeichen lang sind. Tatsächlich ist das gesuchte Wort darunter. Das Wortproblem, wie es in Fachkreisen genannt wird, ist für Typ-1-Grammatiken lösbar.
Es gibt nun wiederum Typ-1-Grammatiken, die darüber hinaus als Typ-2-Grammatiken bezeichnet werden. Eine Grammatik ist vom Typ 2, wenn alle linken Seiten der Umformungsregeln aus genau einem Nichtterminal bestehen. Die oben beispielhaft verwendete Typ-1-Grammatik
ist also auch vom Typ 2. Es sind zwei Regeln. Die linke Seite ist in beiden Fällen nur das Startsymbol

Erkennt man, dass eine Grammatik vom Typ 2 ist, kommt man in den Genuss einiger komfortabler Erleichterungen, die leider nicht generell gelten. Zum Beispiel kann man für Typ-2-Grammatiken entscheiden, ob die erzeugte Sprache leer ist. Die Sprache, die die folgende Grammatik erzeugt, ist die leere Menge:

Diese Grammatik liegt in Chomsky-Normalform (CNF) vor: Alle Regeln haben die Struktur bzw. Alle Typ-2-Grammatiken lassen sich in CNF umformen. An solch einer Normalform kann man leicht überprüfen, ob die generierte Sprache leer ist.


Wie kommt man nun darauf? Das Ziel ist es ja, aus dem Startsymbol Satzformen abzuleiten, die nur aus Terminalzeichen bestehen. Man markiert also alle Regeln der Form denn nur diese bilden am Ende der Ableitungsbäume die Wörter der Sprache. Diese Grammatik hat nur eine solche Regel: Als nächstes markiert man alle Regeln der Form wobei und schon linke Seiten markierter Regeln sind. In diesem Fall kommt dafür nur in Frage. Man weiß jetzt, dass man nicht nur aus sondern auch aus Terminale bilden kann. Den letzten Schritt wiederholt man so lange, bis man keine weitere Regel mehr markieren kann. Dieser Punkt ist bei dieser Grammatik jetzt schon erreicht. Unter den markierten Regeln ist aber keine mit dem Startsymbol auf der linken Seite. Das heißt, es gibt keinen von ausgehenden Ableitungspfad, der zu einem Wort führt, das nur aus Terminalen besteht. Die erzeugte Sprache ist leer.







Typ-2-Grammatiken nennt man auch kontextfrei, denn die Ersetzung eines Terminals hängt nicht von den umgebenden Symbolen ab. In einer Typ-1-Grammatik – einer kontextsensitiven Grammatik – kann es auch solch eine Regel geben:
Das heißt, kann nur dann durch ersetzt werden, wenn es in einem gewissen Kontext steht; wenn es von und eingeschlossen ist. Eine Grammatik, bei der der Kontext keine Rolle spielt, ist programmiertechnisch leichter umzusetzen. Deshalb widmete Noam Chomsky den kontextfreien Grammatiken einen eigenen Typ in seiner Hierarchie.





- Nur für kontextfreie. Da jeder Knoten des Baumes nur ein Nichtterminal und jedes Blatt nur ein Terminal ist, kann man keinen Ableitungsbaum für eine Ableitung aufstellen, bei der mehrere Symbole auf einmal ersetzt werden.

- Sie ist nicht leer. Es gibt die Regel und und lassen sich zu Terminalen ableiten. Die Sprache enthält das Wort „01“ neben unendlich vielen anderen.

Tag 4[Bearbeiten]
Manche kontextfreien Grammatiken sind außerdem regulär (Typ 3). Die Einschränkung für reguläre Grammatiken ist, dass alle Produktionsregeln die Form bzw. haben, wobei ein Terminal und und Nichtterminale sind. Das Äquivalenzproblem ist lösbar. Das Wortproblem ist, im Gegensatz zu anderen kontextsensitiven Grammatiken, effizient lösbar.


Die Chomsky-Hierarchie besteht aus vier Grammatiktypen. Die Typen 0 bis 2 kennst du schon. Jetzt fehlt nur noch Typ 3. Die Menge der Typ-3-Grammatiken ist nun wieder eine Teilmenge der Menge der Typ-2-Grammatiken. Es gibt also kontextfreie Grammatiken, die zusätzlich regulär sind. Die Regeln von Typ-3-Grammatiken haben auf der linken Seite nur ein Nichtterminal, weil es sich um Typ-2-Grammatiken handelt. Außerdem gibt es keine -Regeln, weil sie auch Typ-1-Grammatiken sind und deshalb die linken Seiten nicht länger als die rechten Seiten der Produktionsregeln sein dürfen. Die besondere Einschränkung für reguläre gegenüber allen anderen kontextfreien Grammatiken ist nun, dass die rechten Seiten entweder ein Terminal oder ein Terminal und ein Nichtterminal sein müssen. Alle Regeln haben also die Struktur oder Man kann entweder die Form oder zulassen. Die Menge der Sprachen, die von solchen Grammatiken beschrieben werden können, bleibt die gleiche. Es herrscht weitgehend Einigkeit darüber, dass die Regeln die Form haben. Ganz wichtig ist aber, dass man innerhalb einer Grammatik nicht die Varianten mischt, denn dann ist es keine reguläre Grammatik mehr.


Für reguläre Grammatiken ist das Äquivalenzproblem lösbar. Das heißt, die Fragestellung, ob zwei gegebene Grammatiken genau die gleiche Sprache erzeugen, lässt sich beantworten, sofern es sich um reguläre Grammatiken handelt. Eine weitere Eigenschaft regulärer Grammatiken ist, dass das Wortproblem nicht nur entscheidbar ist, sondern das auch noch sehr effizient. Entscheidbar ist das Problem ja generell für kontextsensitive Grammatiken. Aber für reguläre Grammatiken gibt es sehr schnelle Algorithmen, die feststellen, ob ein gegebenes Wort Element der Sprache ist oder nicht.
Es folgt eine zusammenfassende Darstellung der Chomsky-Hierarchie:
- Typ-0- oder rekursiv aufzählbare Grammatiken (keine Einschränkungen)
- Typ-1- oder kontextsensitive Grammatiken (Für alle Ableitungen bzw. Produktionsregeln gilt )
- Typ-2- oder kontextfreie Grammatiken (Für alle Produktionsregeln gilt )
- Typ-3- oder reguläre Grammatiken (Für alle Produktionsregeln gilt )
- Typ-2- oder kontextfreie Grammatiken (Für alle Produktionsregeln gilt )
- Typ-1- oder kontextsensitive Grammatiken (Für alle Ableitungen bzw. Produktionsregeln gilt )





- Ja. Sie kann mit der folgenden regulären Grammatik beschrieben werden:
Alle Sprachen mit nur endlich vielen Wörtern lassen sich mit regulären Grammatiken beschreiben.

Tag 5[Bearbeiten]
Es gibt keine Grammatiken, die nicht vom Typ 0 sind, aber es gibt Sprachen, die nicht von Typ-0-Grammatiken beschrieben werden können. Die Typen überträgt man auch auf Sprachen.
Die Begriffe rekursiv aufzählbar, kontextsensitiv, kontextfrei und regulär bezieht man auch auf Sprachen, die von solchen Grammatiken erzeugt werden. Erst hier wird der Typ 0 sinnvoll. Es gibt nämlich durchaus Sprachen, die nicht von Grammatiken beschrieben werden können. Das sind genau die Sprachen, die eben nicht vom Typ 0 und nicht rekursiv aufzählbar sind. Es gibt einen schönen Beweis für diese Behauptung:
Sprachen sind meistens unendliche Mengen. Endliche Sprachen, also solche, die nur eine bestimmte Anzahl an Wörtern enthalten, sind immer regulär, denn man kann sie mit einer regulären Grammatik beschreiben. Für Nicht-Typ-0-Sprachen kommen also tatsächlich nur unendliche Sprachen in Frage. Der Kern jeder Grammatik, die Menge der Produktionsregeln, ist aber stets eine endliche Menge. Es gibt keine Grammatik mit unendlich vielen Regeln, denn sonst könnte man diese nicht direkt aufschreiben, sondern müsste sie auch wieder mittels einer Grammatik definieren. Hier dreht sich die Überlegung im Kreis. Im Endeffekt ist jede Grammatik endlich. Die Menge aller Grammatiken ist zwar unendlich, aber rekursiv aufzählbar. Man kann also irgendwo anfangen und systematisch alle Grammatiken aufzählen, obwohl man mit dieser Aufgabe nie fertig würde. Im Gegensatz dazu kann man aber die Menge aller Sprachen als Menge von unendlichen Objekten nicht systematisch aufzählen. Es ist, als würde man versuchen, alle reellen Zahlen aufzuzählen. Es geht noch nicht einmal in einem bestimmten Intervall. Deshalb ist es nicht möglich, jeder Grammatik eine Sprache zuzuordnen und umgekehrt. Es gibt unendlich viele Grammatiken und es gibt unendlich viele Sprachen. Aber dennoch gibt es mehr Sprachen als Grammatiken. Es gibt Sprachen, die nicht von Grammatiken beschrieben werden können. Die, die von Typ-0-Grammatiken beschrieben werden können, heißen rekursiv aufzählbare Sprachen.
In den folgenden Wochen wirst du mehr über reguläre, kontextfreie, kontextsensitive und rekursiv aufzählbare Sprachen lernen.
- 0, 1, 2, 3, 4, …
- die Quadratzahlen
- die ganzen Zahlen
- die Wörter, die aus den Buchstaben a, b und c bestehen
-
- 0, 1, 4, 9, 16, …
- 0, 1, −1, 2, −2, 3, −3, …
- ε, a, b, c, aa, ab, ac, ba, bb, bc, ca, cb, cc, aaa, aab, aac, aba, …
Rückblick[Bearbeiten]
Lies dir heute die Zusammenfassungen noch einmal durch. Wenn du sehr viel Zeit und Lust hast, kannst du natürlich auch alles lesen. Gehe kurz die Übungen der vergangenen Tage durch und versuche dich dann an diesen:

- Alle linken Seiten sind ausschließlich einzelne Nichtterminale. Es handelt sich also um eine kontextfreie Grammatik. Den Einschränkungen für reguläre Grammatiken entspricht diese aber nicht. Man kann genauer sagen: Es ist eine kontextfreie, nicht reguläre Grammatik.
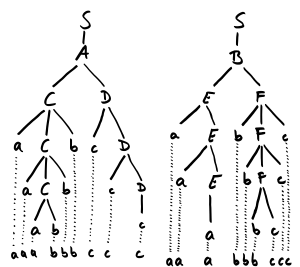
Das sind die beiden möglichen Ableitungsbäume. Die Grammatik ist also mehrdeutig. Die Sprache, die sie beschreibt, ist sogar inhärent mehrdeutig.
