
Digitale bildgebende Verfahren: Digitale Bilder


Vorwort | Grundlagen | Beleuchtung | Bildaufnahme | Lichtwandlung | Digitale Bilder | Wiedergabe | Transformationen | Literatur
Dieses Kapitel beschäftigt sich hauptsächlich mit digitalen, zweidimensionalen Rasterbildern. Diese sind im Allgemeinen rechteckig begrenzt, also mit parallelen, geraden Kanten, die in den Ecken in rechten Winkeln aufeinanderstehen.
Dies entspricht zum einen sowohl der historischen Herangehensweise mit photographischen Platten, die aus praktischen Erwägungen rechtwinklig aus Glas hergestellt werden, als auch mit Filmmaterial, wo die Kanten der Bilder parallel beziehungsweise rechtwinklig zu den Filmstreifen angeordnet werden.

Zum anderen ergibt sich aber bei der digitalen Verarbeitung der Rasterbilddaten mit Computern eine wichtige Randbedingung, die die effiziente Implementierung von Rechenalgorithmen betrifft. In Computern werden zweidimensionale Daten ähnlich wie in Tabellen spalten- und reihenweise in Datenfeldern (englisch: Arrays) gespeichert. Die Kontrollstrukturen, mit denen Computerprogramme erstellt werden können, benutzen ganzzahlige Indizes, mit denen einzelne Spaten oder Reihen sehr effizient bearbeitet werden können. Auch die Adressierung von benachbarten Datenfeldern funktioniert über diese Indices sehr einfach und effizient, was für viele Bildbearbeitungsalgorithmen ausgenutzt wird.
Viele allgemeine Eigenschaften digitaler Bilder sind unabhängig von der Frage, ob die Bilder mehrfarbig oder monochrom sind. Auf die Farben in digitalen Bildern wird aber in mehreren Abschnitten eingegangen.
Digitale Berechnung[Bearbeiten]

Digitale Bilder können direkt mit einem Computer erstellt werden, indem ein geeignetes Computerprogramm digital gespeicherte Messwerte oder Anweisungen eines Benutzers intern umsetzt.
Einfache Beispiele sind Computerprogramme zur Tabellenkalkulation, die Zahlen auch graphisch darstellen können, oder Programme zur Erstellung von Vektorgraphiken.
Bild- und Videobearbeitungsprogramme können aus bereits digital vorliegenden Ausgangsdaten (zum Beispiel auch Rohdaten) veränderte Bilder oder Bilderfolgen berechnen. Dies wird sehr häufig eingesetzt, um die Bilder so zu transformieren, so dass die subjektiv wahrgenommene oder aber auch die objektive Bildqualität verbessert wird. Dabei kann eine Vielzahl von verschiedenen Bildparametern variiert werden, wie zum Beispiel die Helligkeit, der Kontrast, der Kontrastverlauf, die Farben, die Bildauflösung ober die Ausrichtung bis hin zu perspektivischen Verzerrungen oder Montagen mehrerer Bilder.
Vektorisierung[Bearbeiten]
Bei digitalen Bildern, die aus einzelnen Bildpunkten zusammengesetzt sind, gibt es keine informationstechnischen Verknüpfungen oder Beziehungen zwischen den Bildpunkten, die über das rechteckige und rechtwinklige Anordnen der Bildpunkte hinausgehen.
Benachbarte Punkte können dieselbe Helligkeit oder Farbe aufweisen, ohne dass dies in den Bilddaten kodiert ist. Solche Beziehungen zwischen zusammengehörigen Bildpunkten können mit geeigneter Software erstellt oder in vorhandenen gerasterten Bildern ermittelt werden. Typische Beispiele für auszeichenbare topographische Gebilde in digitalen Bildern sind isolierte Punkte, gerade oder nach bestimmten Regeln gekrümmte Linien oder durch geschlossene Linienzüge begrenzte Flächen mit oder ohne Füllung, die auch als graphische Primitive bezeichnet werden. Die Orte der zur Beschreibung dieser Gebilde verwendbaren Punkte - seien es Anfangs-, End- oder Eckpunkte - können mathematisch durch Vektoren definiert werden.
Die graphischen Objekte können bei der Anzeige – auch bei einem Punktdurchmesser oder einer Strichstärke von null – minimal mit dem Durchmesser der dargestellten Bildpunkte wiedergegeben werden. Es ist aber auch möglich, den Punkten einen definierten Durchmesser oder den Linien eine bestimmte Breite zuzuordnen, so dass diese dann gegebenenfalls auch mit mehr als einem Bildpunkt dargestellt werden.
Vektorisierte Bilddaten haben eine Reihe von Vorteilen:
- Die Datenmenge für die vektorielle Beschreibung von einigen wenigen geeigneten Punkten ist oft erheblich geringer als die Datenmenge für die Beschreibung aller beteiligten Punkte in einem Punktraster
- Vektoren können mit einfachen mathematischen Transformationen beliebig skaliert, gedreht, gespiegelt oder verschoben werden
- Mit Vektoren können Abbildungen auch ohne weiteres in drei- oder mehrdimensionalen Räumen realisiert werden, wobei sich die Datenmenge im Vergleich zu gerasterten Daten dann nochmals drastisch reduzieren kann. Mittels geeigneter mathematischer Projektionen lassen sich ohne großen Aufwand zweidimensionale Ansichten, Schnitte oder Perspektiven der Bilddaten erzeugen
Auf der anderen Seite gibt es auch Gründe, die für die Verwendung von gerasterten Bilddaten sprechen:
- Bei einer optischen Abbildung stehen die Informationen über die Beziehungen von benachbarten Punkten nicht unmittelbar zur Verfügung, sondern müssen mit aufwendigen Verfahren im Anschluss an die Aufnahme ermittelt werden
- Bei Bildern mit sehr heterogener Verteilung der Helligkeiten und Farben ist es in der Regel sehr schwierig, Bezüge zwischen benachbarten Punkten herzustellen
- Bei komplexen Bildern wird die Datenmenge zur vollständigen Beschreibung der Bildinhalte mit Vektoren deutlich größer als bei gerasterten Daten
- Gerasterte Daten lassen sich zur Reduktion der Datenmenge meist sehr effizient komprimieren, ohne dass es zu wesentlichen Informationseinbußen kommt
Diese Aspekte führen dazu, dass vektorisierte Daten insbesondere bei der manuellen Erstellung von Bilddaten Verwendung finden (Graphik) und gerasterte Daten vorwiegend bei der maschinellen Erstellung anfallen (Photographie, bildgebende Verfahren).
Wie auch immer, es ist meist leicht möglich, Vektorgraphiken in Rasterdaten umzuwandeln. Als Parameter muss dann die Punktdichte oder die gewünschte Bildauflösung des gesamten Bildes vorgegeben werden, mit der es wiedergegeben werden soll.
Umgekehrt ist es meist deutlich schwieriger, insbesondere wenn die gerasterten Vorlagen schlechten Kontrast oder eine schlechte Auflösung haben. Eine besondere Form der Vektorisierung ist die optische Schriftzeichenerkennung (auch OCR für englisch: Optical Character Recognition), die in großem Umfang zur Umwandlung von gerasterten Textvorlagen in Textdokumente eingesetzt wird.
Bilddateiformate[Bearbeiten]
Es gibt eine Vielzahl von Dateiformaten für gerasterte Bilddaten (englisch: bitmap). Zu den am weitesten verbreiteten allgemein verwendbaren Formaten gehören zum Beispiel:
- JPEG (englisch: Joint Picture Expert Group = Gemeinsame Bildexperten-Gruppe), das eine flexible Datenkompression sowie vorgegebene und proprietäre Metadaten zulässt, jedoch je nach Qualität und Stärke der Datenreduktion immer mit einem mehr oder weniger starken Informationsverlust behaftet ist und von allen Webbrowsern wiedergegeben werden kann
- DNG (englisch: Digital Negative = digitales Negativ) als Nachfolger von TIFF (englisch: Tagged Image File Format = Mit „Anhängern“ (Attributen) versehenes Dateiaustauschformat) zur verlustfreien Speicherung von Rohdaten und Metadaten, das nur in Anspielung auf den Umkehrfilm als „Negativ“ bezeichnet wird, obschon die Bildinformation in aller Regel ohne die Umkehrung von Farb- und Helligkeitswerten gespeichert wird
- PNG (englisch: Portable Network Graphics = portierbare Netzwerkgraphik) mit verlustfreier Datenkompression ist der Nachfolger von GIF (Graphics Interchange Format = Graphikaustauschformat) und kann von allen Webbrowsern wiedergegeben werden
Es ist zu beachten, dass die meisten Speicherformate für gerasterte Bilddaten wegen der Adressierung von Graphikspeicher in Rechenmaschinen den Koordinatenursprung (0 | 0) links oben im Bild haben. Die positive horizontale Achse verläuft also von links oben nach rechts und die positive vertikale Achse von links oben nach unten.
Typische Dateiformate für vektorisierte Graphiken sind:
- DXF (englisch: Drawing Exchange Format = Zeichnungsaustauschformat)
- SVG (englisch: Scalable Vector Graphics = skalierbare Vektorgraphik) mit ausschließlich zweidimensionalen Vektoren und kann von allen Webbrowsern wiedergegeben werden
- PostScript, das als Seitenbeschreibungssprache vor allem für die Druckausgabe entwickelt wurde, aber auch das PDF (englisch: Portable Document Format = portierbares Dokumentenformat) beeinflusst hat, als Encapsulated PostScript (abgekapseltes PostScript) für einzelne graphische Druckseiten verwendet wird und auch zur Einbettung und Speicherung von gerasterten Daten verwendet werden kann
Bildeigenschaften digitaler Bilder[Bearbeiten]
Einige Bildeigenschaften spielen nur im Zusammenhang mit digitalen Bildern eine Rolle, da die entsprechenden Größen und Zusammenhänge bei analogen Bildern nicht vorhanden sind. In den folgenden Abschnitten finden sich daher einige für digitale Bilder wichtige und wesentliche Eigenschaften.
Bildauflösung[Bearbeiten]
Ein sehr wichtiger Parameter für digitale Rasterbilder ist die Bildauflösung oder Pixelzahl. Diese kann entweder als 2-Tupel (, ) mit der Angabe der Bildpunkte in der Bildbreite und in der Bildhöhe oder als Produkt dieser beiden Werte angegeben werden:




Als Maßeinheit für die Anzahl der Bildpunkte wird in der Regel Pixel beziehungsweise Megapixel verwendet.
In der Regel sind die Bildpunkte quadratisch, so dass das Verhältnis exakt das geometrische Verhältnis beim wiedergegebenen Bild widerspiegelt. Obwohl die Diagonale die Bildpunkte unregelmäßig schneidet, kann die effektive Anzahl der Bildpunkte entlang der Bilddiagonalen mit Hilfe des Satzes des Pythagoras über die folgende Beziehung ermittelt werden:


Bildseitenverhältnis[Bearbeiten]

Das Bildseitenverhältnis wird als das Verhältnis der Anzahl der Bildpunkte in der Breite zur Anzahl der Bildpunkte in der Höhe angegeben:


Umgeformt ergibt sich:


Das Verhältnis wird oft als ganzrationale Zahl mit einem Doppelpunkt und nicht mit einem Bruchstrich oder als reelle Zahl angegeben:

Mit dem Bildseitenverhältnis können die Bildauflösung beziehungsweise die Bildbreite und die Bildhöhe berechnet werden:



Auch die effektive Anzahl der Bildpunkte auf der Bilddiagonalen kann gegebenenfalls über das Bildseitenverhältnis ausgerechnet werden:

Oder erneut nach der Bildbreite und der Bildhöhe umgeformt:


Für die Anzahl der Bildpunkte ergibt sich dann:

Das Bildseitenverhältnis von 4:3 stammt vom analogen Fernsehen und wurde für die ersten Computer-Monitore übernommen - die meisten digitalen Kameras haben daher Bildsensoren mit diesem nativen Bildseitenverhältnis; auch die ersten digitalen Camcorder hatten Bildsensoren im Verhältnis 4:3.
Das Bildseitenverhältnis 3:2 stammt aus der analogen Photographie mit Kleinbildfilm; es wird auch bei vielen digitalen Spiegelreflexkameras eingesetzt, wo dieses feste Bildseitenverhältnis auch durch die optischen Sucher vorgegeben ist.
Bei Videoanwendungen hat sich das Bildseitenformat 16:9 durchgesetzt, das sich auch bei den entsprechenden Wiedergabegeräten, wie digitalen Fernsehgeräten und Projektoren, sowie teilweise auch bei Computer-Monitoren wiederfindet. Beim DVD-Format gab es zunächst noch viele ältere Wiedergabegeräte mit dem Bildseitenverhältnis 4:3 und dann zunehmend neuere Wiedergabegeräte mit dem Bildseitenverhältnis 16:9. Die Bildpunkte dieses Formates sind nicht quadratisch und können bei den Wiedergabegeräten eingestellt werden.
Bildformate[Bearbeiten]
In der folgenden Tabelle sind einige wichtige digitale Bildformate angegeben:
| Bildformat Bezeichnung |
Anzahl der Bildpunkte in Pixel |
Anzahl der Bildpunkte in Pixel |
Anzahl der Bildpunkte in Megapixel |
Bildseitenverhältnis |
|---|---|---|---|---|
| VGA | 640 | 480 | 0,3 | 4:3 |
| DVD | 720 | 576 | 0,4 | 4:3 oder 16:9 |
| SVGA | 800 | 600 | 0,5 | 4:3 |
| XGA | 1024 | 768 | 0,8 | 4:3 |
| HD ready | 1280 | 720 | 0,9 | 16:9 |
| SXGA | 1280 | 1024 | 1,3 | 5:4 |
| UXGA | 1600 | 1200 | 1,9 | 4:3 |
| Full HD | 1920 | 1080 | 2,0 | 16:9 |
| QXGA | 2048 | 1536 | 3,1 | 4:3 |
| 4K | 3840 | 2160 | 8,3 | 16:9 |
| 8K | 7680 | 4320 | 33,2 | 16:9 |
Siehe hierzu auch: Bildsensoren
Bit-Tiefe[Bearbeiten]
Die Bit-Tiefe gibt an, in welchem dynamischen Umfang Helligkeitsunterschiede in digitalen Bildern gespeichert werden können. Der maximale Helligkeitswert ergibt sich aus der Anzahl der Bits, die für einen ganzzahligen Wert zur Verfügung stehen:


Die minimale Helligkeit liegt bei 0.
Die möglichen digitalen Helligkeitswerte liegen also im Bereich von 0 bis :

- mit


Diese Überlegungen gelten sowohl für die Helligkeit in Graustufenbildern, als auch für die einzelnen Farbkanäle in Farbbildern, wo dann von der Farbtiefe gesprochen wird. Bei den drei Farbkanälen rot, grün und blau, die den Primärfarben entsprechen, ergibt sich für die digitalen Helligkeitswerte dieser drei Farben dementsprechend:
- mit


- mit


- mit


Bei den standardisierten Dateiformaten JPEG (Joint Picture Expert Group) und PNG (Portable Network Graphics) sowie vielen anderen verbreiteten Dateiformaten für farbige Bilder stehen für die drei Primärfarben jeweils acht Bits (also drei Mal ein Byte) zur Verfügung, so dass also für jeden Punkt und für jeden Farbkanal 256 verschiedene, ganzzahlige Helligkeitswerte von 0 bis 255 gespeichert werden können.
In den folgenden monochromen Bildern wird die Bit-Tiefe jeweils um eins erniedrigt, so dass die Anzahl der zur Verfügung stehenden Graustufen sich jeweils halbiert. Im letzten Bild existieren nur noch zwei Helligkeitsstufen:
- Testtafeln mit abnehmender Bit-Tiefe und Anzahl der Graustufen
-
 Bit-Tiefe 8 mit 256 Graustufen
Bit-Tiefe 8 mit 256 Graustufen -
 Bit-Tiefe 7 mit 128 Graustufen
Bit-Tiefe 7 mit 128 Graustufen -
 Bit-Tiefe 6 mit 64 Graustufen
Bit-Tiefe 6 mit 64 Graustufen -
 Bit-Tiefe 5 mit 32 Graustufen
Bit-Tiefe 5 mit 32 Graustufen -
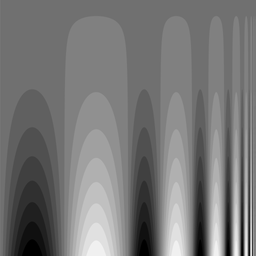 Bit-Tiefe 4 mit 16 Graustufen
Bit-Tiefe 4 mit 16 Graustufen -
 Bit-Tiefe 3 mit 8 Graustufen
Bit-Tiefe 3 mit 8 Graustufen -
 Bit-Tiefe 2 mit 4 Graustufen
Bit-Tiefe 2 mit 4 Graustufen -
 Bit-Tiefe 1 mit 2 Graustufen
Bit-Tiefe 1 mit 2 Graustufen








Bei Rohdatenspeicherung werden in der Regel mehr als acht Bits pro Farbkanal gespeichert, je nachdem welche Genauigkeit und Dynamik der Bildwandungsprozess und der Analog-Digital-Wandler haben. Rohdatenformate sind oft nicht nur für einzelne Anbieter proprietär, sondern häufig sogar für einzelne Geräte. Dies macht den Einsatz von spezieller Software beziehungsweise speziellen Zusatzmodulen (sogenannten Plug-Ins) erforderlich, die in späteren Zeiten möglicherweise nicht mehr frei verfügbar oder zugänglich sind. Mit dem Dateiformat DNG (englisch: Digital Negative = digitales Negativ) wurde ein standardisiertes Rohdatenformat geschaffen, das zunehmend Unterstützung findet.
Speicherbedarf[Bearbeiten]
Stehbilder[Bearbeiten]

Der Speicherbedarf (englisch: memory) in Bytes (1 Byte = 8 Bit) lässt sich für ein einzelnes Bild aus der Anzahl der Farbkanäle , der Bit-Tiefe pro Farbkanal und der Bildauflösung ermitteln:




Nicht-komprimierte, monochrome Bilddaten mit einer Bit-Tiefe von 8 Bits benötigen daher genauso viele Bytes, wie sie Bildpunkte beinhalten. Ist eine höhere Helligkeitsauflösung mit einer Bit-Tiefe von 16 Bits erforderlich, um zum Beispiel die Nachbearbeitung von Bildausschnitten zu ermöglichen, ergibt sich ein doppelt so großer Speicherbedarf. Monochrome Bilder benutzen in der Regel nur einen Farbkanal, Farbbilder werden jedoch üblicherweise mit drei Farbkanälen gespeichert, die den drei Primärfarben rot, grün und blau (RGB) entsprechen, wodurch sich der Speicherbedarf gegenüber monochromen Bilddaten verdreifacht. Wenn für jeden der drei Farbkanäle b Bit zur Verfügung stehen, um die Helligkeit der jeweiligen Primärfarbe zu bestimmen, ergeben sich nach dem folgenden Zusammenhang insgesamt Möglichkeiten:

- , bei b = 8 Bit also


In der folgenden Tabelle finden sich einige Beispielwerte für nicht-komprimierte, dreifarbige Bilder mit einer Bit-Tiefe von 8 Bits pro Farbkanal:
| Bildauflösung in Megapixels |
Speicherbedarf in Megabytes |
|---|---|
| 1 | 3 |
| 2 | 6 |
| 4 | 12 |
| 8 | 24 |
| 16 | 48 |
| 32 | 96 |
Durch geeignete und hochwertige Bildkompressionsverfahren - zum Beispiel unter Verwendung des weit verbreiteten JPEG-Formats, das mit drei Farbkanälen (RGB) und einer Bit-Tiefe von 8 Bit pro Farbkanal definiert ist - lässt sich der Speicherbedarf ohne nenn- oder erkennbare Verluste oft auf etwa 10 Prozent der unkomprimierten Werte reduzieren.
Bewegtbilder[Bearbeiten]
Bei mehreren Bildern in Folge wächst der Speicherbedarf bei verlustfreier Speicherung mit der Anzahl der Bilder und somit auch mit der Zeit . In der Regel wird mit einer Bildfrequenz (beziehungsweise Bildrate) gerechnet, um die erforderliche Datenübertragungsrate [beziehungsweise Datenrate) zu bestimmen:






Der Speicherbedarf für eine Aufnahme der Dauer beträgt dann:

Durch Datenkompression um den Faktor kann die Datenmenge um ein bis zwei Größenordnungen reduziert werden, ohne dass es zu gravierenden Einbußen bei der Bildqualität kommt:




Dies gelingt insbesondere dadurch, dass unveränderte Bildausschnitte nur einmal kodiert und für mehrere aufeinanderfolgende Bilder verwendet werden. Die Kompression kann umso besser gelingen, je mehr Rechenleistung in den Analyseprozess gesteckt werden kann. Daher ist es einfacher, die digitalen Daten ohne Zeitdruck zu komprimieren, als diese zum Beispiel für Live-Übertragungen in Echtzeit zu kodieren. Bei der Kompression kommt es auch im letzteren Fall zwangsweise zu einer Verzögerung, die je nach Datenmenge, Rechenleistung und Verfahren mehrere Sekunden in Anspruch nehmen kann. Bei schnell veränderlichen Filmszenen und zu geringen Datenraten kommt es hierbei sehr häufig zu sogenannten Kompressionsartefakten, wie der Klötzchen- respektive Blockbildung (kachelartige Strukturen im Bild) oder dem Bildruckeln (ruckartiger seitlicher Versatz von aufeinanderfolgenden Bildern).
In der folgenden Tabelle sind einige für verschiedene Situationen erforderlichen Datenmengen zusammengestellt, wobei in allen Fällen von zum einen von rohen Farbbildern mit drei Farbkanälen und einer Bit-Tiefe von jeweils 8 Bit und zum anderen von einer Datenkompression mit dem Faktor ausgegangen wurde:

| Bildauflösung in Megapixels |
Speicherbedarf pro Einzelbild in Megabytes |
Bildfrequenz in Bildern pro Sekunde |
Datenrate in Megabytes pro Sekunde |
Speicherbedarf für eine Stunde in Terabytes |
Speicherbedarf für eine Stunde bei k=100 in Gigabytes |
|---|---|---|---|---|---|
| 0,44 (SD 4:3) | 1,3 | 25 | 33 | 0,12 | 1,2 |
| 0,92 (HD ready) | 2,8 | 25 | 70 | 0,25 | 2,5 |
| 2,1 (Full HD) | 6,2 | 50 | 310 | 1,1 | 11 |
| 8,3 (4K) | 25,9 | 50 | 1200 | 4,3 | 43 |
| 33,2 (8K) | 99,5 | 50 | 5000 | 18 | 180 |

Bildbearbeitung[Bearbeiten]
Dank schneller digitaler Datenverarbeitung können digitale Bilder in kurzer Zeit analysiert und verändert werden. Oft findet eine umfangreiche Bildbearbeitung bereits unmittelbar nach der Aufnahme der Bilddaten mit Hilfe einer Firmware innerhalb von optischen, digitalen Geräten statt. Es besteht aber auch die Möglichkeit weitgehend unbearbeitete Daten, sogenannten Rohdaten zu speichern. Eine Bildbearbeitung kann aber auch nach dem Speichern der Bilddaten in einer Datei zu einem beliebigen späteren Zeitpunkt mit einer geeigneten Software erfolgen. Das Ergebnis einer solchen Bearbeitung wird in der Regel in einer weiteren Datei gespeichert, damit die Originaldaten für eventuell später erforderliche Prozesse erhalten bleiben.
In den folgenden Abschnitten werden einige wichtige Verfahren und Begriffe in diesem Zusammenhang beschrieben.
Digitalzoom - Softwarelupe[Bearbeiten]

Ohne Digitalzoom hat das Objektiv eine Modulationsübertragung, die erheblich über den Erfordernissen eines menschlichen Betrachters liegt. Bei zweifachem Digitalzoom sind die Kontraste für den menschlichen Betrachter noch fast ohne Einschränkungen, bei vierfachem Digitalzoom gibt es bereits deutliche Einbußen, und bei achtfachem Digitalzoom sind die Kontraste erheblich reduziert.
Bei digitalen Bildern ist es sehr leicht möglich, nur einen rechteckigen Ausschnitt des gesamten Bildes zu betrachten. Hierbei ändern sich bei konstanter Brennweite sowohl der Abbildungsmaßstab als auch der Bildwinkel, so dass ein Effekt wie bei der vollständigen Aufnahme mit einer entsprechend längeren Brennweite entsteht.
Es ist allerdings zu beachten, dass ein solcher digital gezoomter Ausschnitt über weniger Bildpunkte verfügt als das Gesamtbild und die Bildauflösung somit reduziert ist. Dies ist solange kein Problem, wie das verwendete Wiedergabegerät beim Einsatz der sogenannten Softwarelupe nicht mehr Bildpunkte hat, als der gewählte Bildausschnitt, da dann höchstens so viele Informationen vorhanden sind, wie dargestellt werden können. Wird der Digitalzoom noch weiter erhöht, müssen die für die Anzeige erforderlichen Punkte (, ) zum Beispiel durch Interpolation oder Punktverdopplung aus den verfügbaren Bildpunkten (, ) berechnet werden, wobei sich allerdings für den Betrachter kein Informationsgewinn ergibt, sondern die Bilder bei hinreichend genauer Betrachtung nur grob gerastert beziehungsweise unscharf wirken, da die Modulationsübertragungsfunktion dabei immer ungünstiger wird.




Siehe hierzu auch: Modulationsübertragung
Üblicherweise wird der Digitalzoom als Faktor oder in Prozent angegeben, wobei sich dieser Wert auf die Längenskalierung und nicht auf die Flächenskalierung bezieht, also:



beziehungsweise

- Digitalzoom - Tiger mit der Anzeige...
-
 ...eines Viertels der verfügbaren Bildpunkte entlang der Bildkanten
...eines Viertels der verfügbaren Bildpunkte entlang der Bildkanten
; -
 ...der Hälfte der verfügbaren Bildpunkte entlang der Bildkanten
...der Hälfte der verfügbaren Bildpunkte entlang der Bildkanten
; -
 ...aller verfügbaren Bildpunkte
...aller verfügbaren Bildpunkte
; -
 ...doppelt so vieler Bildpunkte entlang der Bildkanten wie verfügbar
...doppelt so vieler Bildpunkte entlang der Bildkanten wie verfügbar
; -
 ...viermal so vieler Bildpunkte entlang der Bildkanten wie verfügbar
...viermal so vieler Bildpunkte entlang der Bildkanten wie verfügbar
;















Wird bei optischen Geräten zur Bildaufnahme vor der Aufnahme das Bild auf einem Monitor oder in einem elektronischen Sucher wiedergegeben („Live-View“), kann mit Hilfe der Softwarelupe ein beliebiger Ausschnitt des Bildes mit einhundertprozentigem Digitalzoom dargestellt werden. Dies ist besonders zur Einstellung der korrekten Entfernung am Objektiv sehr hilfreich, hilft aber beispielsweise auch beim Erkennen von Bildrauschen.
Histogramme[Bearbeiten]

Histogramme sind Diagramme, die die Häufigkeitsverteilung der diskreten Helligkeiten in digitalen Bildern angeben. Dabei ist es üblich, auf der horizontalen Achse die Helligkeitswerte (respektive Tonwerte) von dunkel nach hell aufzutragen und bei jedem ganzzahligen Helligkeitswert die Anzahl der im gesamten Bild (oder einem vorher zu definierenden Teilbereich) auftretenden Bildpunkte in vertikaler Richtung anzugeben.
Histogramme können für die gesamte Luminanz oder auch getrennt nach Farbkanälen ausgegeben werden.
Gammakorrektur[Bearbeiten]
Um die mittleren Helligkeiten eines digitalen Bildes anzupassen, ohne die minimale Helligkeit (schwarz) und die maximale Helligkeit (weiß) zu ändern, kann eine rechnerische Gammakorrektur durchgeführt werden.
Siehe Gammakorrektur.
Tonwertkorrektur[Bearbeiten]
Die Helligkeitswerte, gegebenenfalls auch nach Farbkanälen getrennt betrachtet, werden auch Tonwerte genannt.
Weißpunkt[Bearbeiten]
Wenn der Spielraum der Tonwerte in einem digitalen Bild nicht ausgenutzt wird - bei unterbelichteten Bildern ist dies üblicherweise der Fall, da die höheren Helligkeitswerte nicht auftauchen -, ist es sinnvoll, die Helligkeitswerte gleichmäßig zu erhöhen, damit bei der Wiedergabe ein klares Bild mit der Möglichkeit von schwarzen und weißen Bildpunkten entsteht.
Siehe auch Weißpunkt.
Weißabgleich[Bearbeiten]
Eine Tonwertkorrektur kann auch separat für alle vorhandenen Farbkanäle, meist die Primärfarben rot, grün und blau, durchgeführt werden. Um einen Bildbereich farbneutral, also ohne Farbstich, zu bekommen, müssen die entsprechenden Tonwerte der Farbkanäle auf die gleichen Helligkeiten gerechnet werden - diesen Vorgang bezeichnet man als Weißabgleich. Bei Aufnahmesystemen mit automatischem Weißabgleich kann in jedem Farbkanal der hellste Punkt gesucht werden, und mit deren Tonwerten werden die Korrekturen für die einzelnen Farbkanäle ausgerechnet.
Siehe auch Weißabgleich.

Als photographisches Hilfsmittel gibt es Graukarten, die vor der eigentlichen Aufnahme zur manuellen Einstellung des Weißabgleichs eines Aufnahmesystems verwendet werden können. Auch weiße Karten finden hierzu Anwendung, jedoch besteht hierbei unter Umständen die Gefahr einer Überbelichtung, die die Messergebnisse verfälschen würde. Bei weißen Referenzflächen ist also darauf zu achten, dass die Tonwerte nicht in der Sättigung sind.
Bildfehler[Bearbeiten]
Helligkeitsrauschen[Bearbeiten]

Beim Helligkeitsrauschen (Luminanzrauschen) handelt es sich um eine zufällige, mehr oder weniger stark sichtbare Schwankungen bei den Leuchtdichten einzelner Punkte im Bild (siehe auch Kapitel Leuchtdichte), die bei digitalen Bildsensoren durch das Dunkelstromrauschen, durch den Ausleseprozess und durch das Quantisierungsrauschen der Analog-Digital-Wandler verursacht werden. Bei Halbleitern kann der Dunkelstrom und somit das Dunkelstromrauschen durch Kühlung drastisch reduziert werden. Bei einer Erwärmung um mehrere Kelvin verdoppelt sich das Dunkelstromrauschen von Bildsensoren typischerweise.
Simulierte Bilder[Bearbeiten]
Im Folgenden wird das Aussehen von Helligkeitsrauschen anhand eines von einer digitalen Kamera aufgenommenen schwarz-weißen Musters demonstriert, dem künstlich und zunehmend ein farbloses 1/f-Rauschen hinzugefügt wurde.
-
 100% Muster, 0% Helligkeitsrauschen
100% Muster, 0% Helligkeitsrauschen -
 75% Muster, 25% Helligkeitsrauschen
75% Muster, 25% Helligkeitsrauschen -
 50% Muster, 50% Helligkeitsrauschen
50% Muster, 50% Helligkeitsrauschen -
 25% Muster, 75% Helligkeitsrauschen
25% Muster, 75% Helligkeitsrauschen -
 0% Muster, 100% Helligkeitsrauschen
0% Muster, 100% Helligkeitsrauschen





Rauschreduktion[Bearbeiten]
In der nächsten Zusammenstellung ist der Effekt einer nachträglichen Rauschreduktion in den Bildern zu erkennen. Meist werden die Kontrastanteile bei hohen Ortsfrequenzen verringert, wobei allerdings auch die entsprechenden Strukturen, die nicht auf dem Rauschen beruhen, eliminiert werden können. Da bei einer Rauschreduktion häufig extrem große und kleine Helligkeiten eliminiert werden, kann der Bildkontrast nach der Rauschreduktion oft erhöht werden, indem der Weißpunkt und der Schwarzpunkt der Bilder optimiert werden.
-
25% Muster, 75% Helligkeitsrauschen, ohne Rauschreduktion
-
 25% Muster, 75% Helligkeitsrauschen, mit Rauschreduktion
25% Muster, 75% Helligkeitsrauschen, mit Rauschreduktion -
 25% Muster, 75% Helligkeitsrauschen, mit Rauschreduktion, Kontrast erhöht
25% Muster, 75% Helligkeitsrauschen, mit Rauschreduktion, Kontrast erhöht


Gaußsche Weichzeichnung[Bearbeiten]
Ein sehr einfach zu implementierendes Verfahren zur Rauschreduktion ist der Gaußsche Weichzeichner. Hierbei werden die Helligkeiten der einzelnen Bildpunkte mit den Helligkeiten in der Umgebung gewichtet gemittelt. Je mehr Punkte in der Umgebung dazu herangezogen werden, desto niedrigere Ortsfrequenzen werden in ihrer Modulation verringert, so dass die Bilder zunehmend grob strukturiert werden, wobei es keine schnellen Kontrastwechsel mehr gibt. Bei zu starker Weichzeichnung verschwindet nicht nur das Bildrauschen, sondern auch jegliche beabsichtigte Struktur in den Bildern, so dass auch diese schließlich gar nicht mehr erkannt werden können.
-
25% Muster, 75% Helligkeitsrauschen, ungefiltert
-
 25% Muster, 75% Helligkeitsrauschen, gefiltert mit einer Weite von einem Bildpunkt
25% Muster, 75% Helligkeitsrauschen, gefiltert mit einer Weite von einem Bildpunkt -
 25% Muster, 75% Helligkeitsrauschen, gefiltert mit einer Weite von zwei Bildpunkten
25% Muster, 75% Helligkeitsrauschen, gefiltert mit einer Weite von zwei Bildpunkten -
 25% Muster, 75% Helligkeitsrauschen, gefiltert mit einer Weite von vier Bildpunkten
25% Muster, 75% Helligkeitsrauschen, gefiltert mit einer Weite von vier Bildpunkten -
 25% Muster, 75% Helligkeitsrauschen, gefiltert mit einer Weite von acht Bildpunkten
25% Muster, 75% Helligkeitsrauschen, gefiltert mit einer Weite von acht Bildpunkten




Farbrauschen[Bearbeiten]

Beim Farbrauschen (Chrominanzrauschen) handelt es sich um eine zufällige, mehr oder weniger stark sichtbare Schwankungen bei den Farbwerten einzelner Bildpunkte, die die gleichen Ursachen haben wie das Helligkeitsrauschen.
Die folgende Zusammenstellung zeigt Aufnahmen einer nicht reflektierenden schwarzen Scheibe in heller Umgebung, die bei verschiedenen Empfindlichkeiten (ISO-Zahlen) sowohl als kameraintern bearbeite JPEG-Datei als auch als kameraintern unbearbeitete Rohdaten-Datei gespeichert wurden. Zur besseren Erkennbarkeit wurden die geringen Helligkeiten durch eine Gamma-Korrektur bei allen Aufnahmen im gleichen Maße aufgehellt. Bei der Kompaktkamera sind auch bei niedrigen ISO-Werten (geringe Empfindlichkeit mit geringem Bildrauschen) unbunte Bildsignale vorhanden, die auf Falschlicht in der optischen Abbildung zurückzuführen sind:
- Bildrauschen bei verschiedenen Kameraeinstellungen
-
 Kompaktkamera bei ISO 100 als JPEG-Datei
Kompaktkamera bei ISO 100 als JPEG-Datei -
 Kompaktkamera bei ISO 100 als Rohdaten-Datei
Kompaktkamera bei ISO 100 als Rohdaten-Datei -
 Spiegelreflexkamera bei ISO 100 als JPEG-Datei
Spiegelreflexkamera bei ISO 100 als JPEG-Datei -
 Spiegelreflexkamera bei ISO 100 als Rohdaten-Datei
Spiegelreflexkamera bei ISO 100 als Rohdaten-Datei -
 Kompaktkamera bei ISO 200 als JPEG-Datei
Kompaktkamera bei ISO 200 als JPEG-Datei -
 Kompaktkamera bei ISO 200 als Rohdaten-Datei
Kompaktkamera bei ISO 200 als Rohdaten-Datei -
 Spiegelreflexkamera bei ISO 200 als JPEG-Datei
Spiegelreflexkamera bei ISO 200 als JPEG-Datei -
 Spiegelreflexkamera bei ISO 200 als Rohdaten-Datei
Spiegelreflexkamera bei ISO 200 als Rohdaten-Datei -
 Kompaktkamera bei ISO 400 als JPEG-Datei
Kompaktkamera bei ISO 400 als JPEG-Datei -
 Kompaktkamera bei ISO 400 als Rohdaten-Datei
Kompaktkamera bei ISO 400 als Rohdaten-Datei -
 Spiegelreflexkamera bei ISO 400 als JPEG-Datei
Spiegelreflexkamera bei ISO 400 als JPEG-Datei -
 Spiegelreflexkamera bei ISO 400 als Rohdaten-Datei
Spiegelreflexkamera bei ISO 400 als Rohdaten-Datei -
 Kompaktkamera bei ISO 800 als JPEG-Datei
Kompaktkamera bei ISO 800 als JPEG-Datei -
 Kompaktkamera bei ISO 800 als Rohdaten-Datei
Kompaktkamera bei ISO 800 als Rohdaten-Datei -
 Spiegelreflexkamera bei ISO 800 als JPEG-Datei
Spiegelreflexkamera bei ISO 800 als JPEG-Datei -
 Spiegelreflexkamera bei ISO 800 als Rohdaten-Datei
Spiegelreflexkamera bei ISO 800 als Rohdaten-Datei -
 Kompaktkamera bei ISO 1600 als JPEG-Datei
Kompaktkamera bei ISO 1600 als JPEG-Datei -
 Kompaktkamera bei ISO 1600 als Rohdaten-Datei
Kompaktkamera bei ISO 1600 als Rohdaten-Datei -
 Spiegelreflexkamera bei ISO 1600 als JPEG-Datei
Spiegelreflexkamera bei ISO 1600 als JPEG-Datei -
 Spiegelreflexkamera bei ISO 1600 als Rohdaten-Datei
Spiegelreflexkamera bei ISO 1600 als Rohdaten-Datei -
 Spiegelreflexkamera bei ISO 3200 als JPEG-Datei
Spiegelreflexkamera bei ISO 3200 als JPEG-Datei -
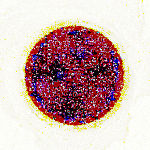 Spiegelreflexkamera bei ISO 3200 als Rohdaten-Datei
Spiegelreflexkamera bei ISO 3200 als Rohdaten-Datei






















Smear-Effekt[Bearbeiten]
Videoaufnahme mit der Demonstration des Smear-Effektes bei einer CCD-Kamera durch das Ein- und Ausschalten einer hellen Lichtquelle im Bildfeld:
- Smear-Effekt
-
 Taschenlampe aus - ohne Smear-Effekt
Taschenlampe aus - ohne Smear-Effekt -
 Taschenlampe an - mit Smear-Effekt (senkrechter rosafarbener Streifen auf Höhe der Lichtquelle)
Taschenlampe an - mit Smear-Effekt (senkrechter rosafarbener Streifen auf Höhe der Lichtquelle)


Vorwort | Grundlagen | Beleuchtung | Bildaufnahme | Lichtwandlung | Digitale Bilder | Wiedergabe | Transformationen | Literatur