
Ing Mathematik: Numerisches Lösen von linearen Gleichungssystemen
Einleitung
[Bearbeiten]
Lineare Gleichungssysteme kommen in der Technik häufig vor. In der Mathematik lernt man in Einführungsvorlesungen z. B. das Gauß-Verfahren als händisches Verfahren zur Lösung linearer Gleichungssysteme kennen, dann aber i. A. für Matrizen mit nur wenigen Zeilen/Spalten. Nun treten in der Praxis (z.B. beim Finite-Elemente-Verfahren) aber Gleichungssysteme mit Tausenden Zeilen auf. Diese händisch zu lösen ist unmöglich. Auch mit einem "computerisierten" Gauß-Verfahren stößt man an die Grenzen von Speicherplatz und Rechenzeit. Aus diesem Grunde wurden zur numerischen Lösung linearer Gleichungssysteme eine Vielzahl von verfeinerten und spezialisierten Verfahren entwickelt. Dies ist nach wie vor ein aktives Feld von mathematischer Forschung. Das nachfolgende Bild gibt einen ersten Eindruck von der Vielfalt an Verfahren (es sind aber nicht alle verfügbaren Verfahren dargestellt).

Als Ingenieur muss man jetzt normalerweise nicht jedes einzelne Verfahren bis ins Detail kennen (dafür gibt es spezialisierte Mathematiker). Zumal die bereits vorgestellten Computersprachen (Octave, Python etc.) schon Funktionen zur Lösung linearer Gleichungssysteme bereitstellen. Mit diesen wird man möglicherweise schon das Auslangen finden. Wenn nicht, dann benötigt man tiefergehende Kenntnisse.
Lineare Gleichungssysteme bei Wikipedia
[Bearbeiten]- Lineares Gleichungssystem
- Direktes Verfahren
- Gaußsches Eliminationsverfahren
- Cholesky-Zerlegung
- Householdertransformation
- Givens-Rotation
- Jacobi-Verfahren
- Fixpunktiteration
- Gauß-Seidel-Verfahren
- SOR-Verfahren
- Splitting-Verfahren
- Mehrgitterverfahren
- Krylow-Unterraum-Verfahren
- Lanczos-Verfahren
- CG-Verfahren
- BiCG-Verfahren
- GMRES-Verfahren
- Kondition
- Vorkonditionierung
- etc.
Direkte vs. iterative Verfahren
[Bearbeiten]Gegeben sei ein lineares Gleichungssystem . heiße Koeffizientenmatrix, ist der Lösungsvektor und die bekannte rechte Seite des Gleichungssystems. n sei die Anzahl der Unbekannten des Gleichungssystems.




Ein direktes Verfahren liefert nach einer endlichen Zahl von Rechenschritten den Lösungsvektor. Ein iteratives Verfahren verbessert schrittweise eine Anfangsnäherung. Direkte Verfahren werden bis zu ca. n = 10000 eingesetzt. Iterative Verfahren eignen sich insbesondere für Gleichungssysteme mit n 10000. (Quelle: [1])

Lineare Gleichungssysteme mit Python und SciPy lösen
[Bearbeiten]Das Python-Paket SciPy stellt zahlreiche Solver zur Verfügung. Nachfolgend seien diesbezügliche Beispiele dargestellt. Details zu den einzelnen Solvern folgen später.
Der "Standardsolver"
[Bearbeiten]Quellcode:
import scipy.linalg
A = [[ 3, 0, -2, 0, 0],
[ 0, 6, 0, 0, 0],
[ 0, 0, -12, 1, 0],
[ 0, 0, 1, 0, 0],
[ 0, 0, 0, 10, 7]]
b = [5, -4, 2, 7, 1]
x = scipy.linalg.solve(A, b)
print(x)
Ausgabe:
[ 6.33333333 -0.66666667 7. 86. -122.71428571]
Einige Krylov-Unterraum-Solver
[Bearbeiten]Quellcode:
import numpy as np
from scipy.sparse import csc_matrix
from scipy.sparse.linalg import bicg, gmres, cgs
A = csc_matrix([[ 3, 0, -2, 0, 0],
[ 0, 6, 0, 0, 0],
[ 0, 0, -12, 1, 0],
[ 0, 0, 1, 0, 0],
[ 0, 0, 0, 10, 7]])
b = np.array([5, -4, 2, 7, 1])
x1, exitCode1 = bicg(A, b)
x2, exitCode2 = gmres(A, b)
x3, exitCode3 = cgs(A, b)
print(x1)
print(x2)
print(x3)
Ausgabe:
[ 6.33333333 -0.66666667 7. 86. -122.71428571] [ 6.33333333 -0.66666667 7. 86. -122.71428571] [ 6.33333333 -0.66666667 7. 86. -122.71428571]
Das csc in der Funktion csc_matrix steht ausgeschrieben für Compressed Sparse Column. Details zu dieser Funktion siehe z.B. in der SciPy-Dokumentation [2]. Generell ist es empfehlenswert diese Dokumentation bei spezifischen Fragen zu bemühen.
Direkte Verfahren
[Bearbeiten]Das gaußsche Eliminationsverfahren
[Bearbeiten]
Ohne Pivotierung
[Bearbeiten]Hier sei ein Programm zu diesem Thema in der Sprache Python in der einfachsten Variante gezeigt. Generell ist zu sagen, dass man die von Python und den zugehörigen Bibliotheken (z.B. SciPy) zur Verfügung gestellten Routinen beim konkreten Einsatz bevorzugt verwenden soll (Gründe: Fehlerfreiheit und Performance). Eigene Implementierungen sind nur für Lehr-, Lern- oder Testzwecke sinnvoll. Oder auch für Verfahren und Weiterentwicklungen, für die es keine SciPy-Prozeduren gibt.
Python-Code:
import numpy as np
# Gauss-Solver
def gauss(A, b):
n = b.shape[0]
x = np.zeros((n,1))
for p in np.arange(0, n):
for i in np.arange(p+1, n):
c_ip = A[i,p] / A[p,p]
b[i] -= c_ip * b[p]
for k in np.arange(p, n):
A[i,k] -= c_ip * A[p,k]
for i in np.arange(n-1, -1, -1):
x[i] = b[i]
if i<n:
for k in np.arange(i+1, n):
x[i] -= A[i,k] * x[k]
x[i] /= A[i,i]
return x
# Hauptprogramm
A = np.array([[ 3., 1., 2., 1., 1.],
[-1., 2., -1., 3., 2.],
[ 0., 2., 4., 3., 9.],
[-4., -4., 3., 5., -1.],
[-5., 3., 1., 0., -7.]])
b = np.array([5., -4., -2., 0., -1.])
x = gauss(A, b)
print(x)
Ausgabe:
[[ 1.22537669] [-0.21141951] [ 1.08929421] [ 0.02410785] [-0.66740682]]
Im Buch Burg, Haf, Wille, Meister: Höhere Mathematik für Ingenieure, Band II: Lineare Algebra. 7. Auflage, Springer Vieweg, 2012, Seite 91 ist dieser Algorithmus in der Programmiersprache MATLAB implementiert. MATLAB ist weitgehend kompatibel mit GNU Octave. Das dort abgedruckte Programm funktioniert somit auch mit Octave (bei Interesse siehe man im genannten Buch).
Dieses Verfahren ohne Pivotierung versagt, wenn im Laufe der Berechnung ein Diagonalelement auftritt. Dann kann das Gauß-Verfahren mit Pivotierung (aus dem französischen, pivot, Dreh- oder Angelpunkt) eine Lösungsmöglichkeit darstellen.

Mit Pivotierung
[Bearbeiten]Bricht obiges Verfahren ab, weil ein Diagonalelement ist, so kann dies mit einer Pivotierung behoben werden. Vorausgesetzt natürlich die Koeffizientenmatrix ist regulär. Dabei werden Zeilen vertauscht (oder auch Spalten). Man spricht dann von Zeilen-, Spalten- oder Totalpivotierung. Eine Pivotierung kann auch im Sinne der Minimierung von Rundungsfehlern sinnvoll sein. Nachfolgend wird das Gauß-Verfahren mit Spaltenpivotierung gezeigt.
Python-Code:
import numpy as np
# Gauss-Solver mit Spaltenpivotierung
def gauss_piv(A, b):
n = b.shape[0]
x = np.zeros((n,1))
for p in np.arange(0, n):
#Spaltenpivotierung
max = np.abs(A[p,p])
ind = p
for j in np.arange(p+1, n):
if max < np.abs(A[j,p]):
ind = j
if ind > p:
tmp = b[p]
b[p] = b[ind]
b[ind] = tmp
for j in np.arange(p, n):
tmp = A[p,j]
A[p,j] = A[ind,j]
A[ind,j] = tmp
# Ende Spaltenpivotierung
for i in np.arange(p+1, n):
c_ip = A[i,p] / A[p,p]
b[i] -= c_ip * b[p]
for k in np.arange(p, n):
A[i,k] -= c_ip * A[p,k]
for i in np.arange(n-1, -1, -1):
x[i] = b[i]
if i<n:
for k in np.arange(i+1, n):
x[i] -= A[i,k] * x[k]
x[i] /= A[i,i]
return x
# Hauptprogramm
A = np.array([[ 3., 1., 2., 1., 1.],
[-1., 2., -1., 3., 2.],
[ 0., 2., 4., 3., 9.],
[-4., -4., 3., 5., -1.],
[-5., 3., 1., 0., -7.]])
b = np.array([5., -4., -2., 0., -1.])
x = gauss_piv(A, b)
print(x)
Ausgabe:
[[ 1.22537669] [-0.21141951] [ 1.08929421] [ 0.02410785] [-0.66740682]]
Auch dieses Beispiel findet sich mit Erklärungen als MATLAB/Octave-Programm im Buch Burg, Haf, Wille, Meister: Seite 92ff.
Die LR-Zerlegung
[Bearbeiten]Das Gauß-Eliminationsverfahren (ohne Pivotierung) kann auch als LR-Zerlegung aufgefasst werden.

sei eine linke, eine rechte Dreiecksmatrix. heißt auch linke unipotente Matrix (lauter Einsen in der Hauptdiagonale).


Sind die Matrizen und bekannt, so kann das Gleichungssystem durch Vor- und Rückwärtselimination gelöst werden.
Die Gauß-Elimination mit Pivotierung kann durch Einführung einer Permutationsmatrix durchgeführt werden. Eine Permutationsmatrix geht aus einer Einheitsmatrix durch Vertauschung von Zeilen/Spalten hervor.

Im SciPy-Paket von Python ist z.B. eine Funktion lu (l ... left oder lower, u ... upper) vorhanden, um die LR-Faktorisierung durchzuführen. Mit einer Vor- und Rückwärtselimination kann das lineare Gleichungssystem wieder gelöst werden. Zuvor sei aber noch die Funktionsweise der lu-Funktion gezeigt.
Python-Code:
import numpy as np
from scipy.linalg import lu
A = np.array([[ 3, 0, -2, 0, 0],
[ 0, 6, 0, 0, 0],
[ 0, 0, -12, 1, 0],
[ 0, 0, 1, 0, 0],
[ 0, 0, 0, 10, 7]])
P, L, R = lu(A)
print(P)
print("--------------------------------------")
print(L)
print("--------------------------------------")
print(R)
Ausgabe:
[[1. 0. 0. 0. 0.] [0. 1. 0. 0. 0.] [0. 0. 1. 0. 0.] [0. 0. 0. 0. 1.] [0. 0. 0. 1. 0.]] -------------------------------------- [[ 1. 0. 0. 0. 0. ] [ 0. 1. 0. 0. 0. ] [ 0. 0. 1. 0. 0. ] [ 0. 0. -0. 1. 0. ] [ 0. 0. -0.08333333 0.00833333 1. ]] -------------------------------------- [[ 3. 0. -2. 0. 0. ] [ 0. 6. 0. 0. 0. ] [ 0. 0. -12. 1. 0. ] [ 0. 0. 0. 10. 7. ] [ 0. 0. 0. 0. -0.05833333]]
In der Permutationsmatrix ist zu sehen, dass eine Zeilenvertauschung stattgefunden hat.
Nachfolgend ist der Python-Code für die Gauß-Elimination ohne Pivotierung gezeigt. Er folgt dem Pseudocode im Buch Meister: Numerik linearer Gleichungssysteme. 4. Aufl., Vieweg+Teubner, 2011, Seite 42.
import numpy as np
from scipy.linalg import lu
def lr(A, b):
n = b.shape[0]
x = np.zeros(n)
# LR-Zerlegung
for k in np.arange(0, n-1):
for i in np.arange(k+1, n):
A[i,k] /= A[k,k]
for j in np.arange(k+1, n):
A[i,j] -= A[i,k]*A[k,j]
# Vorwärtselimination
for k in np.arange(1, n):
for i in np.arange(0, k):
b[k] -= A[k,i]*b[i]
# Rückwärtselimination
for k in np.arange(n-1, -1, -1):
for i in np.arange(k+1, n):
b[k] -= A[k,i]*x[i]
x[k] = b[k] / A[k,k]
return x
A = np.array([[ 3., 1., 2., 1., 1.],
[-1., 2., -1., 3., 2.],
[ 0., 2., 4., 3., 9.],
[-4., -4., 3., 5., -1.],
[-5., 3., 1., 0., -7.]])
b = np.array([5., -4., -2., 0., -1.])
x = lr(A, b)
print(x)
Die Ausgabe ist wiederum:
[ 1.22537669 -0.21141951 1.08929421 0.02410785 -0.66740682]
Das Cholesky-Verfahren
[Bearbeiten]
Für positiv definite Matrizen kann auch das Verfahren von Cholesky eingesetzt werden. Positiv definit heißen Matrizen für die Folgendes gilt: für alle und reell und symmetrisch.


Festgestellt werden kann die positive Definitheit mit dem Kriterium von Hadamard (Burg, Haf, Wille, Meister: Seite 194f und 206ff) bzw. dem Satz von Sylvester (siehe Riemer, Seemann, Wauer, Wedig: Mathematische Methoden der Technischen Mechanik. 3. Auflage, Springer, 2019, Seite 10). Beide Sätze oder Kriterien sagen das Gleiche aus, nämlich: Sind alle Hauptminoren der Matrix positiv, so ist die Matrix positiv definit. Es gilt auch die Regel: Eine quadratisch positiv definite Matrix ist immer regulär. Zum Begriff Hauptminor wird ein Beispiel geliefert:

Die Hauptminoren sind folgende Unterdeterminanten:

Die Matrix in diesem Beispiel ist somit positiv definit (weil alle Hauptminoren positiv sind)!. Gleichwertig zum Kriterium von Hadamard ist folgendes: Alle Eigenwerte von sind positiv.
Aber nun wieder zurück zum Cholesky-Verfahren. Die positiv definite Matrix kann zerlegt werden in
. Wobei eine links-untere Dreiecksmatrix ist. Wie diese Matrix ermittelt wird sei hier nicht dargestellt. Dafür gibt es nämlich auch eine SciPy-Funktion namens scipy.linalg.cholesky. Um den Lösungvektor zu ermitteln muss dann nur noch eine Vorwärts- und Rückwärtselimination durchgeführt werden.

Python-Code:
import numpy as np
from scipy.linalg import cholesky
def cholesky_simple(A, b):
n = b.shape[0]
x = np.zeros(n)
# Cholesky-Zerlegung
A = cholesky(A, True)
# Vorwärtselimination
for k in np.arange(0, n):
for i in np.arange(0, k):
b[k] -= A[k,i]*b[i]
b[k] /= A[k,k]
# Rückwärtselimination
for k in np.arange(n-1, -1, -1):
for i in np.arange(k, n):
b[k] -= A[i,k]*x[i]
x[k] = b[k]/A[k,k]
return x
# Hauptprogramm
A = np.array([[1., 2., 3.],
[2., 5., 6.],
[3., 6., 50.]])
b = np.array([5., 9., -1])
x = cholesky_simple(A, b)
print(x)
Ausgabe:
[ 8.17073171 -1. -0.3902439 ]
Will man Genaueres wissen, so sei auf das Buch Meister: Seite 46ff verwiesen. Dort ist auch der Algorithmus zur Bestimmung der Cholesky-Zerlegung in Octave-nahem Pseudocode angegeben.
QR-Zerlegungen - das Householder-Verfahren
[Bearbeiten]
Hierbei wird eine QR-Zerlegung durchgeführt. ist eine orthogonale Matrix. Für orthogonale Matrizen gilt oder . sei die nxn-Einheitsmatrix. Die Transponierung einer Matrix lässt sich viel einfacher als die Invertierung durchführen. Die QR-Zerlegung existiert für alle regulären Matrizen, sie ist aber nicht eindeutig.






Householder-Matrizen sind symmetrisch und orthogonal. Sie lassen sich als beschreiben, . Sie sind Spiegelungen an einer zu senkrechten Ebene (siehe auch nebenstehendes Bild). Es gilt somit auch, wie für jede Spiegelungsmatrix, .





Folgende Darstellung hält sich im Wesentlichen an den konstruktiven Beweis in Burg, Haf, Wille, Meister: Seite 311 und an Knorrenschild: Numerische Mathematik, Eine beispielorientierte Einführung. 6. Aufl., Hanser, 2017, Seite 53ff. Die Darstellung in Meister: Seite 59ff ist komplexer und enthält auch Definitionen, Sätze und Beweise. Auch Hanke-Bourgeois: Seite 120ff liefert eine mathematisch einwandfreie Herleitung, dürfte aber eher Mathematiker ansprechen. Das Householder-Verfahren wird dort auch nicht im Rahmen der linearen Gleichungsysteme eingeführt, sondern für lineare Ausgleichsprobleme.
Es sei eine reguläre nxn-Matrix und die Einheitsmatrix.



Beispiel: Es sei folgendes Gleichungssystem gegeben

1. Schritt:
Sei





2. Schritt:
Wir streichen aus die erste Zeile und Spalte und bekommen






Wir ergänzen wieder um eine erste Einheitszeile und Spalte und erhalten


Als Ergebnis erhalten wir die QR-Zerlegung:


Somit können wir das Gleichungssystem lösen:


Durch Rückwärtselemination erhält man aus

Somit

Man beachte, dass durch die Rundungsfehler bei der Handrechnung nicht genau das exakte Ergebnis herauskommt.
Neben dem Householder-Verfahren sind auch noch das Verfahren mit Givens-Rotationen und das Gram-Schmidt-Verfahren bekannt.
Nachfolgend der Python-Code mit einer QR-Zerlegung. Diese ist aber nicht notwendigerweise eine Householder-Spiegelung.
import numpy as np
import scipy.linalg as la
def qr_simple(A, b):
Q, R = la.qr(A)
x = la.solve(R, np.transpose(Q)@b)
return x
A1 = np.array([[1., 2., 3.],
[2., 5., 6.],
[3., 6., 50.]])
b1 = np.array([5., 9., -1])
A2 = np.array([[2., 1., 0.],
[3., -1., 1.],
[1., -2., 2.]])
b2 = np.array([1., 1., -1])
A3 = np.array([[ 3., 0., -2., 0., 0.],
[ 0., 6., 0., 0., 0.],
[ 0., 0., -12., 1., 0.],
[ 0., 0., 1., 2., 0.],
[ 0., 0., 0., 1., 7.]])
b3 = np.array([5., -4., 2., 7., 1.])
x1 = qr_simple(A1,b1)
print(x1)
x2 = qr_simple(A2,b2)
print(x2)
x3 = qr_simple(A3, b3)
print(x3)
Ausgabe:
[ 8.17073171 -1. -0.3902439 ] [ 0.6 -0.2 -1. ] [ 1.74666667 -0.66666667 0.12 3.44 -0.34857143]
Konditionszahl und Spektralradius
[Bearbeiten]Als Konditionszahl einer Matrix bezüglich einer Norm wird die Zahl bezeichnet. sei eine Norm der Matrix. Es gibt verschiedene Matrixnormen, z.B. Spaltensummennorm, Zeilensummennorm, Spektralnorm, Frobeniusnorm. Die Konditionszahl stellt neben dem Spektralradius die Größe dar, mit der Fehlereinflüsse und Konvergenzgeschwindigkeit iterativer Verfahren abgeschätzt werden. Der Spektralradius ist . ist der jeweilige Eigenwert. Die Konditionszahl gibt die maximale Verstärkung des relativen Fehlers an. Zu weiteren Details (insbesondere Definitionen, Sätze, Beweise) wird auf die am Kapitelende genannten Bücher verwiesen.




Nachfolgend sei noch ein Beispiel zum Begriff Konditionszahl gezeigt:
Die Zeilensummennorm der reellen (3x3)-Matrix

berechnet sich als
.

Die inverse Matrix ist


Die Konditionszahl ist somit
cond

Ist cond, so ist das Problem schlecht konditioniert, sonst gut konditioniert.

Selbstverständlich muss man das nicht händisch rechnen, auch dafür stellt Python Möglichkeiten bereit.
Python-Code:
import numpy as np
A = np.array([[ 1., -2., -3.],
[ 2., 3., -1.],
[-3., 0., 1.]])
A_inv = np.linalg.inv(A)
# Zeilensummennorm
norm = np.linalg.norm(A, np.inf)
norm_inv = np.linalg.norm(A_inv, np.inf)
# Konditionszahl
cond = norm*norm_inv
print(cond)
Ausgabe:
5.076923076923077
Ein Beispiel für den Spektralradius:
Die Eigenwerte einer Matrix lassen sich auch mittels Python-Programm einfach berechnen. Dies sei hier anhand eines Beispiels gemacht (das geht auch für eine 3x3-Matrix schneller und fehlerfreier als die Eigenwerte händisch zu berechnen):
from scipy.linalg import eig
A = [[1., -2., -3.],
[-2., 3., -1.],
[-3., -1., 1]]
lamb, arr = eig(A)
print(lamb)
Im obigen Programm steht lamb für lambda (weil lambda ein Python-Schlüsselwort ist).
Das Programm liefert die Werte
[-2.7875545 +0.j 4.56702956+0.j 3.22052494+0.j]
Daraus folgt für den Spektralradius:

Konvergenz, Konsistenz, Stabilität
[Bearbeiten]Vorerst sei zu diesen Begriffen auf folgende Seiten verwiesen:
Splitting-Verfahren
[Bearbeiten]
Oft treten Matrizen auf, die eine spezielle Struktur haben - Bandmatrizen, auch spärlich besetzte Matrizen oder Sparse-Matrizen genannt. Diese Matrizen sind abseits der Hauptdiagonalen hauptsächlich mit Nullen besetzt. Insbesondere für solche Matrizen gibt es iterative Verfahren. Splitting-Verfahren gehören zu den iterativen Verfahren. Splitting-Methoden spalten die Koeffizientenmatrix additiv auf: . Die im nachfolgenden gezeigten Solver unterscheiden sich nur durch die Wahl von . sollte leicht invertierbar sein und eine gute Näherung an darstellen. Warum ist das so? Eine Antwort kann nachfolgende schrittweise Umformung geben:



ist die Iterationmatrix, ein Vektor, somit ist .



Lösungsschritte: . ist der Startvektor und .



Jacobi-Verfahren
[Bearbeiten]
Beim Jacobi- oder Gesamtschrittverfahren wählt man . diag steht für Diagonalmatrix.

.

D.h. lässt sich einfach invertieren.
und

.
Iterationsvorschrift: oder ausgeschrieben


Python-Code:
import numpy as np
def jacobi(A, b, maxit):
n = b.shape[0]
xapp, xnew = np.zeros(n), np.zeros(n)
it = 0
while it < maxit:
for i in np.arange(0, n):
sum = 0.
for j in np.arange(0,n):
if j != i:
sum += A[i,j] * xapp[j]
xnew[i] = (b[i] - sum) / A[i,i]
xapp = xnew
it += 1
return xapp
# Hauptprogramm
A = np.array([[ 3., 0., -2., 0., 0.],
[ 0., 6., 0., 0., 0.],
[ 0., 0., -12., 1., 0.],
[ 0., 0., 1., 2., 0.],
[ 0., 0., 0., 1., 7.]])
b = np.array([5., -4., 2., 7., 1.])
x = jacobi(A, b, 100)
print(x)
Ausgabe:
[ 1.74666667 -0.66666667 0.12 3.44 -0.34857143]
Eine MATLAB/Octave-Variante des Programms findet sich wieder in Burg, Haf, Wille, Meister: Seite 271.
Das Jacobi-Verfahren konvergiert, wenn mindestens eines der folgende Kriterien erfüllt ist:
- Das starke Zeilensummenkriterium: für alle
- Das starke Spaltensummenkriterium: für alle .




Man nennt dann auch strikt diagonaldominant.
Unter bestimmten Kriterien konvergiert das Verfahren auch, wenn nur das schwache Zeilen- oder Spaltensummenkriterium erfüllt ist. Darauf sei hier aber nicht eingegangen.
Zu Details und Ergänzungen zur Konvergenz des Verfahrens siehe z.B. Meister: Seite 76ff oder Hanke-Bourgeois: Grundlagen der Numerischen Mathematik und des Wissenschaftlichen Rechnens. 3. Aufl., Vieweg+Teubner, 2009, Seite 77ff
Gauß-Seidel-Verfahren
[Bearbeiten]
Beim Gauß-Seidel-Verfahren oder Einzelschrittverfahren wird gewählt, mit sei regulär.


ist die strikte links untere Dreiecksmatrix

Dies führt zu , mit





Python-Code:
import numpy as np
def gauss_seidel(A, b, maxit):
n = b.shape[0]
xapp = np.zeros(n)
it = 0
while it < maxit:
for i in np.arange(0, n):
sum = 0.
for j in np.arange(0,n):
if j != i:
sum += A[i,j] * xapp[j]
xapp[i] = (b[i] - sum) / A[i,i]
it += 1
return xapp
# Hauptprogramm
A = np.array([[ 3., 0., -2., 0., 0.],
[ 0., 6., 0., 0., 0.],
[ 0., 0., -12., 1., 0.],
[ 0., 0., 1., 2., 0.],
[ 0., 0., 0., 1., 7.]])
b = np.array([5., -4., 2., 7., 1.])
x = gauss_seidel(A, b, 100)
print(x)
Ausgabe:
[ 1.74666667 -0.66666667 0.12 3.44 -0.34857143]
Eine etwas andere, komplexere Realisierung in Form eines MATLAB/Octave-Programms findet sich in Burg, Haf, Wille, Meister: Seite 279.
Vorteil des Gauß-Seidel-Verfahrens gegenüber dem Jacobi-Verfahren - meist schnellere Konvergenz.
Auch für das Gauß-Seidel-Verfahren gilt bezüglich Konvergenz das starke Zeilensummenkriterium (= strikte Diagonaldominanz).
Relaxationsverfahren
[Bearbeiten]Mit Relaxation kann eine Konvergenzbeschleunigung herbeigeführt werden. Die Abkürzung SOR steht für successive overrelaxation. Relaxationsverfahren werden insbesondere im Buch Meister: Seite 84ff behandelt. Eine kurze Einführung findet sich auch in Burg, Haf, Wille, Meister: Seite 282ff.
Krylov-Unterraum-Verfahren
[Bearbeiten]
Auch die Krylov-Unterraum-Verfahren gehören zu den iterativen Verfahren und dienen dem Lösen großer spärlich besetzter linearer Gleichungssysteme.
Was ist ein Unterraum (siehe auch Unterraum)?
Sei ein Vektorraum über einem Körper . Eine Teilmenge von heißt Unterraum von , wenn



- für alle auch (Abgeschlossenheit bezüglich der Addition) und
- für alle und alle auch (Abgeschlossenheit bezüglich der Skalarmultiplikation) gilt.





Statt kann man auch andere Vektorräume verwenden, z.B. (= komplexe Vektoren).

Das hört sich jetzt kompliziert an. Aber die Definitionen z.B. in Burg, Haf, Wille, Meister: Seite 79 und Bronstein: Taschenbuch der Mathematik. 7. Aufl., Harri Deutsch, 2008, Seite 368 sind auch nicht einfacher.
Für eine lineare Hülle, auch Span oder Abschluss genannt gilt: A spannt den Unterraum U auf, bzw. U = span A ( Lineare Hülle).
Was ist ein Krylov-Unterraum (siehe auch Krylowraum)?
Ein Krylov-Unterraum ist ein Unterraum des Vektorraums , der zu einer quadratischen Matrix , einem Vektor , dem Startvektor der Krylow-Sequenz und einem Index als lineare Hülle iterierter Matrix-Vektor-Produkte definiert ist:




Sei der Residuenvektor.

Die Krylov-Unterraum-Verfahren finden nun meist eine bessere Näherungslösung so, dass der Residuenvektor orthogonal zu allen Vektoren eines Unterraumes steht. Dies kann auch so geschrieben werden: (= Orthogonalitätsbedingung). Die Bedingung heißt Galerkin-Bedingung. Die Krylov-Unterraum-Methoden unterscheiden sich durch die konkrete Wahl des Raumes , sowie durch Ausnutzen von Eigenschaften der Matrix . Dadurch kann das jeweilige Verfahren beschleunigt werden. Andererseits schränkt das aber die Anwendbarkeit ein.




Zu näheren Details und insbesondere zu Sätzen und Beweisen bezüglich Konvergenzverhalten von Krylow-Unterraum-Methoden, zu Unterschieden zu den Splitting-Methoden etc., siehe insbesondere Meister: Seite 119ff.
Die Zusammenhänge zwischen den einzelnen Krylov-Unterraum-Verfahren inkl. Entwicklungsdaten werden auch in Meister: Seite 123, Bild 4.18 übersichtlich dargestellt. Ausgangs- und Angelpunkt ist das CG-Verfahren, das wiederum auf dem Verfahren des steilsten Abstiegs und dem Verfahren der konjugierten Richtungen beruht ( Gradientenverfahren).
Gradientenverfahren
[Bearbeiten]Python-Code:
import numpy as np
def gradientenverfahren(A, b, maxit):
n = b.shape[0]
x = np.zeros(n)
for i in np.arange(0, maxit):
r = b-A@x
q = A @ r
rq = np.transpose(r) @ q
lamb = (np.transpose(r) @ r) / rq
x += lamb * r
r -= lamb * q
return x
# Hauptprogramm
A = np.array([[1., 2., 3.],
[2., 5., 6.],
[3., 6., 50.]])
b = np.array([5., 9., -1])
x = gradientenverfahren(A, b, 1000)
print(x)
Ausgabe:
[ 8.17073171 -1. -0.3902439 ]
Eine deutlich "aufgebohrte" Variante als MATLAB/Octave-Code findet sich in Meister: Seite 233f. Zu Theorie und einem Algorithmus in Pseudocde siehe Meister: Seite 125ff. Man beachte, dass das Gradientenverfahren (auch Methode des steilsten Abstiegs genannt) nur für symmetrisch positiv definite Matrizen funktioniert.
CG-Verfahren
[Bearbeiten]-
 Eduard Stiefel (schweizer Mathematiker, 1909-1978)
Eduard Stiefel (schweizer Mathematiker, 1909-1978) -
 Magnus Hestenes (US-amerikanischer Mathematiker, 1906-1991)
Magnus Hestenes (US-amerikanischer Mathematiker, 1906-1991) -
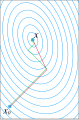 einfaches Gradientenverfahren mit optimaler Schrittlänge (in grün), CG-Verfahren (in rot)
einfaches Gradientenverfahren mit optimaler Schrittlänge (in grün), CG-Verfahren (in rot)



Das CG-Verfahren (CG ... conjugate gradients, konjugierte Gradienten) wurde um 1952 von E. Stiefel und M. Hestenes entwickelt. Es kann zur Lösung von symmetrisch positiv definiten linearen Gleichungssystemen eingesetzt werden.
Wie das CG-Verfahren funktioniert siehe vorerst CG-Verfahren#Idee_des_CG-Verfahrens.
Auch hier wird wieder ein Python-Programm gezeigt. Pseudo- bzw. MATLAB/Octave-Code sind in Meister: Seite 137 und 234f angeführt.
import numpy as np
import scipy.linalg as la
def cg_simple(A, b, maxit):
n = b.shape[0]
x = np.zeros(n)
tol = 1.e-13
r = b - A@x
p = r
normr = la.norm(r)
alpha = normr**2
for i in np.arange(0, maxit):
if normr <= tol:
print("konvergiert: Schritt ", i)
break
v = A @ p
vr = np.transpose(v) @ r
lamb = alpha/vr
x = x + lamb * p
r = r - lamb * v
alpha2 = alpha
normr = la.norm(r)
alpha = normr**2
p = r + alpha/alpha2 * p
return x
# Hauptprogramm
A = np.array([[1., 2., 3.],
[2., 5., 6.],
[3., 6., 50.]])
b = np.array([5., 9., -1])
x = cg_simple(A, b, 500)
print(x)
Ausgabe:
konvergiert: Schritt 6 [ 8.17073171 -1. -0.3902439 ]
Für dieses Verfahren gibt es wieder eine vorgefertigte SciPy-Funktion (siehe z.B. [3]).
import numpy as np
from scipy.sparse import csc_matrix
from scipy.sparse.linalg import cg
A1 = csc_matrix([[4, 0, 1, 0],
[0, 5, 0, 0],
[1, 0, 3, 2],
[0, 0, 2, 4]])
b1 = np.array([-1, -0.5, -1, 2])
A2 = np.array([[1., 2., 3.],
[2., 5., 6.],
[3., 6., 50.]])
b2 = np.array([5., 9., -1])
x1, exit_code = cg(A1, b1)
x2, exit_code = cg(A2, b2)
print(x1)
print(x2)
Ausgabe:
[ 5.03611909e-17 -1.00000000e-01 -1.00000000e+00 1.00000000e+00] [ 8.17073171 -1. -0.3902439 ]
GMRES-Verfahren
[Bearbeiten]Dieses Verfahren wurde 1986 von Y. Saad und M. H. Schultz vorgestellt. Es ist für alle regulären Matrizen einsetzbar. GMRES steht für Generalized Minimal Residual.
Für das Prinzip sei vorerst auf GMRES-Verfahren verwiesen. Oder siehe für Theorie, Pseudocode und MATLAB/Octave-Programm wieder das Buch Meister: Numerik linearer Gleichungssysteme.
Auch für dieses Verfahren gibt es eine SciPy-Funktion scipy.sparse.linalg.gmres. Die Anwendung ist exakt so, wie z.B. für das CG-Verfahren oder auch zu Beginn dieses Kapitels dargestellt.
Vorkonditionierung
[Bearbeiten]Bei der Vorkonditionierung wird ein lineares Gleichungssystem so umgeformt, dass die Lösung erhalten bleibt, dabei aber eine bessere Kondition (Ziel: schnellere Konvergenz) folgt.
Sonstiges
[Bearbeiten]- Ein lineares Gleichungssystem wird übrigens niemals mittels inverser Matrix gelöst. Dies wäre viel zu aufwendig und instabil.
- Genauso wenig werden Determinanten (sofern überhaupt notwendig) via Laplace-Entwicklungsformel berechnet. Auch dafür ist der Gauß-Algorithmus effizienter.
- Die Eigenwerte von symmetrischen reellen Matrizen sind immer reell. Ist die Matrix nur reell, so können auch komplexe Eigenwerte auftreten.
- QR-Zerlegungen werden auch für die numerische Berechnung von Eigenwerten und linearen Ausgleichsproblemen verwendet.

Skripten im WWW
[Bearbeiten]Einfach nach den Stichwörtern "numerische Mathematik Skript" o.ä. googeln. Es finden sich jede Menge Skripten im PDF-Format zu diesem Thema im Internet.
Gedruckte Werke (auszugsweise)
[Bearbeiten]- Burg, Haf, Wille, Meister: Höhere Mathematik für Ingenieure, Band II: Lineare Algebra. 7. Auflage, Springer Vieweg, 2012, ISBN 978-3-8348-1853-9
- Hanke-Bourgeois: Grundlagen der Numerischen Mathematik und des Wissenschaftlichen Rechnens. 3. Aufl., Vieweg+Teubner, 2009, ISBN 978-3-8348-0708-3
- Knorrenschild: Numerische Mathematik, Eine beispielorientierte Einführung. 6. Aufl., Hanser, 2017, ISBN 978-3-446-45161-2
- Meister: Numerik linearer Gleichungssysteme. 4. Aufl., Vieweg+Teubner, 2011, ISBN 978-3-8348-1550-7