
Kernel of a linear map – Serlo
The kernel of a linear map intuitively contains the information that is "deleted" when applying the linear map. Further, the kernel can be used to characterize the injectivity of linear maps. It also plays a central role in solving systems of linear equations.
Introduction
[Bearbeiten]We have learned about special mappings between vector spaces, called linear maps. Those are structure-preserving; that is, they are compatible with addition and scalar multiplication of a vector space. We can therefore think of a linear map from to as something that transports the vector space structure from to .


Introductory examples
[Bearbeiten]We consider two accounts, each with the account balance and respectively. We can describe this information with a vector . The total account balance is the sum of the two account balances. We can calculate it by using the map




This map is linear and therefore transports the vector space structure from to . In the process, information is lost: one no longer knows how the money is distributed among the accounts. For example, one can no longer distinguish the individual account balances and because they both map to the same total account balance . In particular, the mapping is not injective. However, we get the information about how much money is in the accounts in total.






Next, we consider the map

Visually, this corresponds to a counterclockwise rotation of by degrees. By undoing this rotation, one can recover the original vector from any rotated vector in . Formally speaking, this mapping is an isomorphism and no information is lost. In particular, the image of linearly independent vectors is linearly independent again (because an isomorphism is injective, see the article monomorphism) and the image of a generator of is again a generator of (because an isomorphism is surjective, see the article epimorphism).

Finally, we consider a rotation again, but then embed the rotated plane into the :


Although this mapping is no longer bijective, no information is lost here when transporting the vector space structure of the into the : As in the previous example, different vectors in the are mapped to different vectors in the because of injectivity. Linear independence of vectors is also preserved. However, a generating system of is not mapped to a generator of . For example, the linear map sends the standard basis to , which is not a generator of . The property of a set of vectors to be a generator depends on the ambient space. This is not the case with linear independence; it is an "intrinsic" property of sets of vectors.


Derivation
[Bearbeiten]We have seen various examples of linear maps that transport a -vector space into another -vector space, while preserving the structure. In the process, varying amounts of "intrinsic" information from the original vector space (such as differences of vectors or linear independence) were lost. The last example suggests that injective mappings preserve such intrinsic properties. On the other hand, we see: If is not injective, then there are vectors with . So in that case, "eliminates" the difference of and . The difference is again an element in . Since is linear, we can reformulate:









Intuitively, is injective if and only if differences of vectors under are not eliminated (i.e., mapped to zero). Because is structure-preserving, we have that for all and , that implies



If the difference of and is eliminated under , so is that of and . In the same way, if : if and , then also





So the difference of and is also eliminated. The differences eliminated by are themselves vectors in . These are send by to the zero element of and thus, the eliminated vectors are in the preimage . Conversely, any vector can be written as a difference ; that is, the difference between and the zero vector is eliminated by . The preimage measures exactly what differences of vectors (how much "information") is lost in the transport from to . Our considerations show that is even a subspace of . We give a name to this subspace: the kernel of .







Definition
[Bearbeiten]The kernel of a linear map intuitively measures how much "intrinsic" information about vectors from (differences of vectors or linear independence) is lost when applying the map. Mathematically, the kernel is the preimage of the zero vector.
Definition (Kernel of a linear map)
Let and be two -vector spaces and linear. Then we call the kernel of .


In the derivation we claimed that the kernel of a linear map from to is a subspace of . We will now prove this in detail.
Theorem (The kernel is a vector space)
Let be a linear map between the -vector spaces and . Then is a subspace of .

Proof (The kernel is a vector space)
To verify the claim, we need to show four things:
- For all we have that .
- For all and all we have that .






Proof step:
The first assertion follows directly from the definition.
Proof step:
Since is linear, we know that holds. So .

Proof step: For all , we have that .
Now we show the third point: for all it holds that

![{\displaystyle {\begin{aligned}f(v_{1}+v_{2})&=\ f(v_{1})+f(v_{2})\\[0.3em]&\ {\color {OliveGreen}\left\downarrow f{\text{ is linear (i.e., additive)}}\right.}\\[0.3em]&=\ 0_{W}+0_{W}\\[0.3em]&\ {\color {OliveGreen}\left\downarrow v_{1},v_{2}\in \ker f\right.}\\[0.3em]&=\ 0_{W}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6bc00465f23dbfd4421def8bf56021ba260b7705)
So also is in the kernel of .

Proof step: For all and all we have that .
The fourth step works analogously to the third step: For all and all it is true that
![{\displaystyle {\begin{aligned}f(\lambda \cdot v)&=\lambda \cdot f(v)\\[0.3em]&\ {\color {OliveGreen}\left\downarrow f{\text{ is linear (i.e., homogeneous)}}\right.}\\[0.3em]&=\ \lambda \cdot 0_{W}\\[0.3em]&\ {\color {OliveGreen}\left\downarrow v\in \ker f\right.}\\[0.3em]&=\ 0_{W}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0a831a81e0f886a4eb2a35e589ac953acd376c47)
Thus, .
Examples
[Bearbeiten]We determine the kernel of the examples from the introduction.
Vector is mapped to the sum of entries
[Bearbeiten]We consider the mapping

The kernel of is made up by the vectors with , so . In other words



Thus the kernel of is a one-dimensional subspace of . More generally, for we can consider the mapping


Again, by definition, a vector lies in the kernel of if and only if holds. So we can freely choose and then set . Thus






Hence, the kernel of is a -dimensional subspace of . It is also called a hyperplane in .


Rotation in
[Bearbeiten]We consider the rotation

Suppose lies in the kernel of , i.e. it holds that


From this we obtain . So only the zero vector lies in the kernel of and we have that .


is rotated and embedded into the
[Bearbeiten]Next we consider

As in the previous example, we determine the kernel by choosing any vector . Thus it holds that


Again it follows that , so that also for this mapping holds.
Derivatives of polynomials
[Bearbeiten]Finally, we consider a linear map that did not appear in the introduction:
![{\displaystyle f\colon \mathbb {R} [X]\to \mathbb {R} [X],\quad p\mapsto p',}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d5aa1ae243a4998ca357afe066d9cbb278392c9c)
which maps a real polynomial to its derivative. That is, a polynomial

with coefficients is mapped to the polynomial


Graphically, we associate with a polynomial that indicates the gradient of at each point. From this information, we still learn what the shape of the polynomial is (just as if we were given a stencil). However, we no longer know where it is positioned on the -axis, because the information about the constant part of the polynomial is lost when taking the derivative. Polynomials that just differ by a displacement along the -axis can no longer be distinguished after derivation. For example, both and have the derivative . So the mapping maps them to the same polynomial.





The kernel of thus contains exactly the constant polynomials:
![{\displaystyle \ker f=\{p\in \mathbb {R} [X]\mid p=c{\text{ for some }}c\in \mathbb {R} \}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e658601cb73567d844593199a00d11a1269167cf)
The inclusion "" is clear, because the derivative of a constant polynomial is always the zero polynomial. For the converse inclusion "", we consider any polynomial and show that it is constant. We can always write such a polynomial as for some and certain coefficients . Because of it holds that





and by comparison of the coefficients, we obtain . So is constant.

Once the polynomial ring article is written, link to the coefficient comparison in it
Kernel and injectivity
[Bearbeiten]In the derivation above, we saw that a linear map preserves all differences of vectors (i.e., no vector is eliminated) if and only if the kernel consists only of the zero vector. We also saw there that linearity implies: A linear map is injective if and only if no difference of vectors is eliminated. So we have the following theorem:
Theorem (Relationship between kernel and injectivity)
Let and be two -vector spaces and let be linear. Then is injective if and only if . In particular, is injective if and only if .


Summary of proof (Relationship between kernel and injectivity)
For establishing the theorem we have to show two directions:
- If is injective, then .
- From it follows that is injective.

The first direction we directly be shown. For the other direction, we assume and show that for any and with we must have . Here, we can use that for two vectors with , we have . Further, is equivalent to .







Proof (Relationship between kernel and injectivity)
Proof step: If is injective, then .
Let us first assume that is injective. We already know that . Since is injective, it can map at most one argument to one function value. So only is mapped to . Thus , because the kernel is defined as the set of all vectors that meet the zero vector.

Proof step: From we get that is injective.
Let . In order to show that is injective, we consider two vectors and from with . Then


![{\displaystyle {\begin{aligned}f(v_{1}-v_{2})&=\\&{\color {OliveGreen}\left\downarrow f{\text{ is linear}}\right.}\\[0.3em]&=f(v_{1})-f(v_{2})\\&{\color {OliveGreen}\left\downarrow f(v_{2})=f(v_{1})\right.}\\[0.3em]&=\ 0_{W}\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8eb916713f566c6a9db73c5c750ac2e635d1f415)
So . Since we have assumed , it follows that and thus . Hence, we have the implication for all . But this is exactly the definition for being injective.



Proof step: is injective if and only if .
We have already shown that is injective if and only if . It remains to show that this is equivalent to . The kernel of is a subspace of . A subspace of is exactly equal to if its dimension is zero. So is indeed injective if and only if .


Alternative proof (Relationship between kernel and injectivity)
One can also show this theorem with only one chain of equivalent statements:
![{\displaystyle {\begin{aligned}f{\text{ is injective}}&\iff \forall v_{1},v_{2}\in V:\left(v_{1}\neq v_{2}\implies f(v_{1})\neq f(v_{2})\right)\\[0.3em]&\iff \forall v_{1},v_{2}\in V:\left(v_{1}-v_{2}\neq 0_{V}\implies f(v_{1})-f(v_{2})\neq 0_{W}\right)\\[0.3em]&{\color {OliveGreen}\left\downarrow \ f{\text{ is linear}}\right.}\\[0.3em]&\iff \forall v_{1},v_{2}\in V:\left(v_{1}-v_{2}\neq 0_{V}\implies f(v_{1}-v_{2})\neq 0_{W}\right)\\[0.3em]&{\color {OliveGreen}\left\downarrow \ {\text{set }}{\tilde {v}}=v_{1}-v_{2}\right.}\\[0.3em]&\iff \forall {\tilde {v}}\in V:\left({\tilde {v}}\neq 0_{V}\implies f({\tilde {v}})\neq 0_{W}\right)\\[0.3em]&{\color {OliveGreen}\left\downarrow \ f(0_{V})=0_{W}\right.}\\[0.3em]&\iff {\text{Only }}0_{V}{\text{ is mapped to }}0_{W}\\[0.3em]&\iff \ker f=\{0_{V}\}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/77f57329dd06a1ab20cbc35adc6419af62ccc72f)
The larger the kernel is, the more differences between vectors are "eliminated" and the more the mapping "fails to be injective". The kernel is thus a measure of the "non-injectivity" of a linear map.
Injective maps and subspaces
[Bearbeiten]In the introductory examples we conjectured that injective linear maps preserve "intrinsic" properties of vector spaces. By this, we mean properties that do not depend on the ambient vector space, such as the linear independence of vectors or vectors being distinct. The property of being a generator can be lost in injective linear maps, as we have seen in the example of the twisted embedding of into : The mapping is injective, but the standard basis of is not mapped to a generator of .
What exactly does it mean that a property of a family of vectors does not depend on the ambient space ? Often, properties of vectors from (for example, linear independence) depend on the vector space structure of , that is, addition and scalar multiplication. To make dependences as small as possible, we restrict our attention to the smallest subspace of containing , that is, we restrict to . Now, we call a property of intrinsic if it depends only on but not on .



Example (Intrinsic and non-intrinsic properties)
Let be a vector space and a subset of vectors.

- Linear independence of vectors in is an intrinsic property, because the definition of linear independence can also be checked in and does not refer to the ambient vector space .
- Differences of vectors in are also intrinsic properties: all that is needed to examine it are vectors and their difference .
- Not intrinsic, on the other hand, is the property of of being a generator of : The set is always a generator of . But if the ambient space is larger than , then is not a generator of .


What do intrinsic properties of a family of vectors have to do with injectivity? Let be a linear map. Suppose preserves intrinsic properties of vectors, that is, if a family has some intrinsic property, then its image under also has this property. Then also preserves the property of vectors being different, since this is an intrinsic property. That means, if are different, i.e., , then their image under is also different, i.e., . So is injective.



Conversely, if is injective, then is isomorphic to the subspace of : If we restrict the target space of to its image, we obtain an injective and surjective linear map , that is, an isomorphism. In particular, for any family in , it holds that the subspace of is isomorphic to . Thus, the latter has the same properties as and hence, preserves intrinsic properties of subsets of .



So we have seen that is injective if and only if preserves intrinsic properties of subsets of .
Kernel and linear independence
[Bearbeiten]In the previous section we have seen that injective linear maps are exactly those linear maps which preserve intrinsic properties of . The linear independence of a family of vectors is such an intrinsic property, as they either hold for any choice of an ambient space or do not hold for any choice of an ambient space.

So, injective linear maps should preserve linear independence of vectors, i.e., the image of linearly independent vectors is again linearly independent. Conversely, a linear map cannot be injective if it does not preserve the linear independence of vectors, since the intrinsic information of "being linearly independent" is lost.
Overall, we get the following theorem, which has already been proved in the article on monomorphisms:
Theorem (Injective linear maps preserve linear independence)
Let and be two -vector spaces and a linear map. Then holds if and only if the image of every linearly independent subset of is again linearly independent.

In particular, for any linear map , the vector space is a -dimensional subspace of . In the finite-dimensional case, there cannot exist an injective linear map from to if . This has also already been shown in the article on monomorphisms.


Kernel and linear systems
[Bearbeiten]The kernel of a linear map is an important concept in the study of systems of linear equations.
Let be a field and let . We consider a linear system of equations


with variables and rows. We have , where and . We can also write this system of equations using matrix multiplication:







where , and . We denote the set of solutions by




Determining a solution to the linear system of equations for a given right-hand side is the same as finding a preimage of under the linear map



Link where the map "multiply matrices by a given fixed matrix" is studied? Especially where it is explained that it is linear. Possibly also to the article where it is explained how to determine the kernel of a matrix (Gauss), if this is written.
The system of equations has solutions if the preimage is not empty. In this case, we may ask whether there are multiple solutions, that is, whether the solution is not unique. In other words, we are interested in how many preimages a has under .


By definition of injectivity, every point has at most one element in its preimage if and only if is injective. This means that the linear system of equations has at most one solution for each , that is, . Because is linear, injectivity is equivalent to . So we can already state:


Theorem (Uniqueness of solutions)
Let be a field and let , and . Then

Hint
The set of solutions of can be empty. This occurs, for example, when is the zero matrix and . Consequently, the kernel makes no statement about the existence of solutions, only about their uniqueness. To say something about the existence of solutions, we need to consider the image of .



Even if is not injective, i.e., holds, we can still say more about the set of solutions by exploiting the kernel: The difference of two vectors and , which maps to the same vector, lies in the kernel of . Therefore, the preimage of some under can be written as



where is any element of . This is shown by the following theorem:

Theorem (Solution set of linear system and kernel)
Let be a field and let , and . further, let be a solution of the linear system of equations . Then


In particular, a solution of the system of equations is unique if and only if the linear map induced by has a kernel that only consists of the zero vector.
Proof (Solution set of linear system and kernel)
We have to prove the equality . For this we need to establish two subset relations.

Proof step:

Let . Then . The only possible candidate for to satisfy the equation is . Since





we have .

Proof step:

We show that holds for any . Let be arbitrary. Then holds. Since by assumption, is a solution of , we have that



So is also a solution of and thus lies in the set .


We have thus even extended the statement of the theorem above. The larger the kernel of is, that is, the "less injective" the mapping is, the "less unique" are solutions of , if any exist. The set of solutions of a linear system of equations is the kernel of the induced linear map shifted by a particular solution . Furthermore,


The set of solutions of the homogeneous system of equations (that is, with right-hand side zero) is exactly the kernel of .

Hint
As with the previous theorem, no statement is made about whether solutions of exist at all for a given . The kernel only characterizes uniqueness.
Exercises
[Bearbeiten]Exercise (Injectivity and dimension of and )
Let and be two finite-dimensional vector spaces. Show that there exists an injective linear map if and only if .

How to get to the proof? (Injectivity and dimension of and )
To prove equivalence, we need to show two implications. For the execution, we use that every monomorphism preserves linear independence: If is a basis of , then the vectors are linearly independent. For the converse direction, we need to construct a monomorphism from to using the assumption . To do this, we choose bases in and and then use the principle of linear continuation to define a monomorphism by the images of the basis vectors.



Solution (Injectivity and dimension of and )
Proof step: There is a monomorphism

Let be a monomorphism and a basis of . Then is in particular linearly independent and therefore is linearly independent. Thus, it follows that . So is a necessary criterion for the existence of a monomorphism from to .





Proof step: there is a monomorphism

Conversely, in the case we can construct a monomorphism: Let be a basis of and be a basis of . Then . We define a linear map by setting




for all . According to the principle of linear continuation, such a linear map exists and is uniquely determined. We now show that is injective by proving that holds. Let . Because is a basis of , there exist some with





Thus, we get
![{\displaystyle {\begin{aligned}0_{V}=f(x)&=f\left(\sum _{i=1}^{n}\lambda _{i}v_{i}\right)\\[0.3em]&\ {\color {OliveGreen}\left\downarrow \ f{\text{ is linear}}\right.}\\[0.3em]&=\sum _{i=1}^{n}\lambda _{i}f(v_{i})\\[0.3em]&\ {\color {OliveGreen}\left\downarrow \ f(v_{i})=w_{i}\right.}\\[0.3em]&=\sum _{i=1}^{n}\lambda _{i}w_{i}\\[0.3em]&\ {\color {OliveGreen}\left\downarrow \ \lambda _{i}=0{\text{ for }}i>n\right.}\\[0.3em]&=\sum _{i=1}^{m}\lambda _{i}w_{i}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f49ed4d7691d3d680772c9681d2416c4673412cf)
Since are linearly independent, must hold for all . So it follows for that


We have shown that holds and thus is a monomorphism.
Exercise
We consider the linear map . Determine the kernel of .

Solution
We are looking for vectors such that . Let be any vector in for which is true. We now examine what properties this vector must have. It holds that


So and . From this we conclude . So any vector in the kernel of satisfies the condition . Now take a vector with . Then






We see that . In total


Check your understanding: Can you visualize in the plane? What does the image of look like? How do the kernel and the image relate to each other?


We have already seen that

Now we determine the image of by applying to the canonical basis.

So holds. We see that the two vectors are linearly dependent. That is, we can generate the image with only one vector: .


-
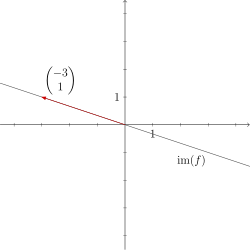 The image of f
The image of f -
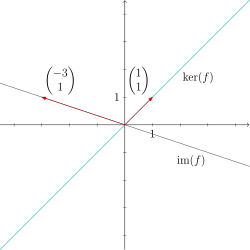 Image and kernel of f together
Image and kernel of f together


In our example, the image and the kernel of the linear map are straight lines through the origin. The two straight lines intersect only at the zero and together span the whole .
Exercise
Let be a vector space, , and be a nilpotent linear map, i.e., there is some such that



is the zero mapping. Show that holds.

Does the converse also hold, that is, is any linear map with nilpotent?
Solution
Proof step: nilpotent

We prove the statement by contraposition. That is we show: If , then is not nilpotent.
Let . Then is injective, and as a concatenation of injective functions, is also injective. By induction it follows that for all the function is injective. But then also for all . Since the kernel of the zero mapping would be all of , the map could not be the zero mapping for any . Consequently, is not nilpotent.




Proof step: The converse implication
The converse implication does not hold. There are mappings that are neither injective nor nilpotent. For example we can define

This mapping is not injective, because . But it is also not nilpotent, because we have for all .


